
































SEO Title: Taxes Title and Fees Calculator API Guide 2026
Meta Description: Build a real estate taxes title and fees calculator with API inputs, rule engines, validation, and monitoring.
Meta Keywords: taxes title and fees calculator, closing cost calculator, real estate API, property tax assessment, proptech engineering, title fees, transfer tax, BatchData
Most advice about a taxes title and fees calculator is aimed at car buyers. That's too small a target.
If you're building software for lenders, investor platforms, brokerage portals, or underwriting teams, the better opportunity is real estate. The same core idea applies, estimate the full transaction cost before commitment, but the engineering burden is far higher because the data is fragmented, the rules are jurisdiction-specific, and the trust requirement is unforgiving.
Core takeaways
- Consumer-style calculators are not enough. Enterprise tools need explainable line items, rule provenance, and versioned calculations.
- Real estate is the harder and more valuable problem. You have to model taxes, title charges, third-party fees, and prepaid items, not just one tax rate plus fixed fees.
- Accuracy starts with location intelligence. A wrong county, district, or parcel match poisons the output.
- Architecture matters. Separate data ingestion, rule evaluation, fee configuration, and audit logging.
- Trust is a feature. If users can't inspect the math, they won't rely on the result.
The useful question isn't whether you can build a calculator. It's whether you can build one that survives real underwriting workflows.
Why Your Next Calculator Should Be for Real Estate
A car-focused taxes title and fees calculator is solved well enough for consumer use. Real estate is not. That gap matters if the software has to support lending, acquisitions, brokerage operations, or disclosure workflows where a bad estimate creates rework, compliance risk, or a broken deal.
The familiar automotive pattern is still useful as a product lesson. Buyers adopted TTL calculators once fees became too material to ignore and too variable to estimate by hand. Real estate pushes that problem much further. A property closing cost calculator has to combine parcel context, jurisdictional taxes, recording rules, title and settlement charges, lender assumptions, and date-sensitive prepaids. The result is closer to financial infrastructure than a shopping widget.
I have seen teams underestimate this because the UI looks simple. A few fields. A total. Maybe a fee table. The hard part sits underneath. County boundaries drift. Recording fees change. Title charges vary by state, by transaction type, and sometimes by local practice. If the engine cannot explain each line item and trace it back to a rule set or source record, operations teams stop trusting it.
That is why a serious closing cost calculator should start with real estate.
Why the automotive model reveals the real estate opportunity
Automotive calculators proved that users will rely on fee estimation tools when price transparency affects purchase decisions. In real estate, the pressure is higher because the estimate can influence underwriting, seller proceeds, cash-to-close expectations, and investor yield models. Approximation does not fail gracefully here. It creates support tickets, manual overrides, and exceptions that spread across the transaction.
The engineering challenge is also more interesting. Vehicle calculators usually evaluate a narrower set of inputs and fee types. Real estate calculators have to handle fee categories with different ownership patterns, update cycles, and legal logic. Transfer taxes may split between parties. Recording fees may depend on document count. Prepaids change with closing date. Title charges often require state-specific treatment, and teams that skip that detail usually end up replacing hand-entered defaults later with a dedicated guide to modeling title company fees.
Practical rule: If the estimate will appear in underwriting, disclosures, or an internal approval flow, build it like a financial system with audit trails and versioned rules.
Where enterprise value shows up
The return is not in publishing a nicer public calculator. It is in building a calculation engine that other systems can call consistently.
| Use case | Why it matters | What breaks toy calculators |
|---|---|---|
| Loan origination | Fee buckets have to map cleanly into lender workflows and disclosures | Hardcoded defaults, weak rule traceability |
| Investor underwriting | Entry costs change basis, yield, and bid strategy | No parcel-level tax context, no bulk execution |
| Seller net sheets | Proceeds need realistic deductions tied to local practice | Missing title, recording, and payoff-sensitive adjustments |
| Portfolio analysis | Teams need repeatable estimates across thousands of assets | Manual inputs, no API-first output, no audit history |
This changes the product brief. The deliverable is not a page with a calculate button. The deliverable is a service that can return a defensible number, a line-item breakdown, source-aware assumptions, and enough metadata for another team to verify the result without opening a spreadsheet.
Deconstructing Real Estate Closing Costs
A real estate taxes title and fees calculator is only as good as its fee taxonomy. If your data model collapses unlike charges into one bucket called "closing costs," your logic will rot fast.
Real estate fees fall into a few operational groups, and each group behaves differently. Some are jurisdictional. Some are vendor-driven. Some are date-sensitive. Some are prepaid balances that change with timing and loan structure rather than local statute.
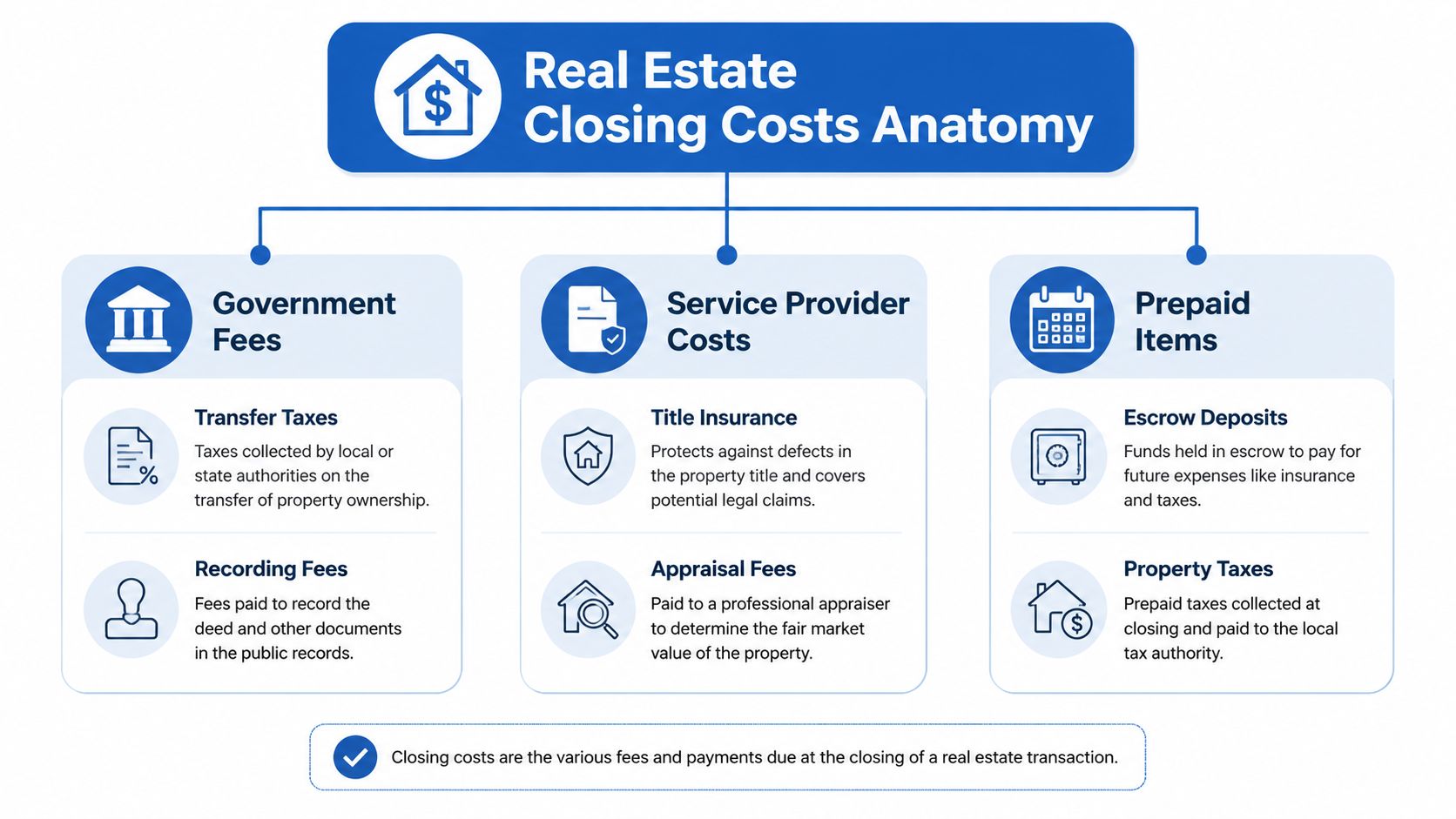
The three cost families you need to model
| Cost family | Typical components | Modeling challenge |
|---|---|---|
| Government fees | Recording charges, transfer taxes, filing-related fees | Jurisdiction-specific and often document-based |
| Service provider costs | Title search, settlement services, appraisal, credit-related items | Vendor variance and negotiated ranges |
| Prepaid items | Property tax escrows, insurance prepaids, daily interest | Timing-sensitive and loan-dependent |
That split matters because each family should sit in a different part of your engine. Government fees belong in rule tables. Service costs often need configurable defaults plus override controls. Prepaids need date logic and scenario inputs.
Government fees are deterministic until they aren't
Government charges look simple, but they usually hide edge cases. A county might record one document at one rate, then charge differently for additional pages, riders, or mortgage-related filings. Local transfer taxes can stack on top of state taxes. Some fees apply only when debt is recorded. Others depend on exemption status or transaction type.
That means your calculator needs:
- A jurisdiction resolver that identifies state, county, city, and special districts
- A rule hierarchy so local rules can override broader defaults
- An effective-date layer because fee schedules change and old closings must remain reproducible
Service provider charges need configuration, not fantasy precision
A lot of teams make the same mistake here. They fake exactness.
If you don't have a live title partner feed or lender-specific vendor schedule, don't present a pseudo-precise number as if it came from an authority. Use a configured estimate range internally, then expose a controlled estimate externally with proper labeling. That's safer and more honest.
For a related look at how these charges get discussed in practice, title company fee breakdowns are useful because they show how quickly "miscellaneous" becomes a blind spot if your categories are too broad.
Existing calculators often stop at upfront TTL logic and miss the connection to property assessment context, liens, and ownership data. That gap can create 20-30% cost variance in some workflows, especially where trade-ins or liens distort the true picture, as noted by Vehicle Tax Calculator's Colorado discussion.
Prepaids are where timing turns into money
Prepaids and escrows aren't optional detail. They're often the reason users think your calculator is "wrong" even when your tax math is correct.
A robust model has to account for:
- Closing date sensitivity, because monthly and annual collection cycles matter
- Loan-dependent escrows, since lender requirements can change the cash-to-close profile
- Property tax posture, including current assessment context and collection schedules
A real estate calculator notably diverges completely from the automotive pattern. Cars mostly ask, "What do I owe today?" Real estate also asks, "What must be reserved, collected, or prorated because of what happens after today?"
Sourcing the Data with APIs and Core Inputs
The engine can't outrun weak inputs. If the address is fuzzy, the parcel match is wrong, or the tax jurisdiction is guessed from ZIP alone, the rest of the math is decoration.
A production calculator starts with a short set of user inputs, then enriches them with external data. Keep the manual form tight. Ask for what the user knows. Fetch what the system should know better.
Start with the minimum human input
The core user inputs are usually enough to initiate the model:
- Property address: Needed for parcel matching and jurisdiction resolution
- Sale price: The base for transfer-related calculations and affordability context
- Loan amount: Required when mortgage-related fees depend on debt being recorded
- Down payment or financing structure: Important for prepaid and escrow logic
Everything beyond that should be pulled, inferred, or selected from validated options whenever possible.
Build an API-first sourcing map
The cleanest way to design this is with a sourcing table. It keeps product, engineering, and compliance aligned on where each number came from.
| Data Point | Source Type | Example Source / API Endpoint |
|---|---|---|
| Property address normalization | User input plus API validation | Address verification or geocoding service |
| Parcel identifier | API call | County parcel match or property data platform |
| Jurisdiction stack | API call | State, county, city, district enrichment from parcel/location data |
| Property tax assessment context | API call | Assessment and tax history endpoint |
| Transfer and recording fee schedules | Static lookup with versioning | Internal fee table maintained from official schedules |
| Loan-dependent charges | User input plus configuration | Lender profile and scenario settings |
| Title and settlement estimates | Configured defaults or partner feed | Vendor-configurable schedule |
| Output trace | Internal system record | Calculation log with rule version IDs |
API discipline matters here. If your team doesn't document payloads and fallback behavior well, downstream consumers will misuse your calculator service. A concise practical API documentation guide for indie makers is worth reading because the same principles apply even in enterprise systems: define required fields, validation states, error modes, and example responses before you scale usage.
Accuracy comes from enrichment, not extra form fields
In proptech workflows, calculator quality is often measured against final invoices. Vehicle Tax Calculator reports that TTL tools benchmark at 92-97% match rates to final invoices, and that BatchData-scale workflows using ML propensity and Snowflake-enriched geo-taxes can reach 99.5% accuracy; it also notes that a bulk endpoint like /ttl/estimate?zip=80521&price=35000 can reduce underwriting cycle time by 40% for real estate investors. The pattern matters more than the automotive framing. Bulk, validated enrichment wins.
A useful mental model is this:
- Humans provide intent
- APIs provide context
- Rules provide determinism
- Logs provide accountability
For teams designing the data pipeline behind these calculations, API integration patterns for tax data and cost trade-offs are especially relevant because tax and assessment inputs rarely live in one clean source of truth.
The fastest way to degrade calculator accuracy is to make users supply values that already exist in public records or internal data feeds. Every unnecessary field is another place for drift.
What works and what doesn't
| Approach | What works | What fails |
|---|---|---|
| User-entered locality | Fast prototype | Wrong county, wrong district, wrong fees |
| ZIP-based estimation | Basic fallback for broad estimates | Poor fit for jurisdiction boundaries and local exceptions |
| Parcel-resolved enrichment | Strong basis for fee and tax logic | Requires reliable matching and refresh strategy |
| Static fee tables only | Fine for narrow markets | Breaks when schedules update or exemptions differ |
The right architecture treats external data as a first-class dependency, not a nice-to-have enhancement.
Engineering the Calculator Logic and Regional Rules
Most calculators fail in the rule layer. The interface looks polished, the address lookup works, and the numbers are still wrong because the computation model assumes flat rules where the jurisdiction uses layered logic.
A resilient taxes title and fees calculator needs a multi-layered, jurisdiction-specific computation engine. That isn't theory. CarWhere's Colorado TTL methodology notes that location error alone accounts for 22% of miscalculations, creating $200-500 discrepancies, and recommends geocode validation plus ZIP-centroid fallback to reach 99% precision in batch processing. That lesson transfers directly to real estate.

Use rules as data, not hardcoded branches
If you hardcode county logic deep in application code, updates become brittle and auditing becomes painful. Put regional logic in versioned configuration.
A practical structure looks like this:
Resolve location
- normalize address
- geocode
- match parcel
- derive jurisdiction stack
Load active rule set
- state rules
- county overrides
- city or district supplements
- effective date filters
Run fee modules
- transfer-related charges
- recording-related charges
- debt-linked fees
- title and third-party configured estimates
- prepaids and prorations
Assemble result
- itemized outputs
- assumptions
- confidence notes
- rule version IDs
This is the difference between a calculator and a fee engine. One answers a question. The other supports operations.
Favor strategy patterns for fee families
Different fee categories want different evaluators. Flat-fee recorders, tiered taxes, exemption-driven logic, and time-sensitive prepaids shouldn't all go through one generic function.
| Rule type | Better implementation choice | Why |
|---|---|---|
| Flat fee | Lookup evaluator | Easy to maintain and audit |
| Tiered fee | Bracket strategy | Supports thresholds and progressive logic |
| Conditional exemption | Rule predicate plus override chain | Captures eligibility conditions cleanly |
| Date-sensitive proration | Time-based calculator module | Avoids mixing temporal logic into tax tables |
That structure also keeps deployments safer. You can patch one evaluator without touching the others.
Treat geocoding as financial infrastructure
A lot of teams still treat location matching as a convenience layer. That's a serious mistake.
If the county is wrong, the transfer charge is wrong. If the special district is missed, the result can be directionally wrong even when the tax formula itself is perfect. That's why geocode validation belongs before rule evaluation, not after. ZIP-centroid fallback should exist, but only as a controlled degradation path with a lower-confidence label.
For teams budgeting the backend work around this sort of engine, a data engineering pricing calculator can help frame the true cost of maintaining rule pipelines, ETL updates, and data contracts. The point isn't the estimate itself. It's recognizing that ongoing rule maintenance is part of the product, not overhead.
For property-specific logic, understanding how property tax assessment works in real estate data pipelines helps because assessment context often decides whether a fee should be estimated, prorated, deferred, or surfaced separately.
Engineering judgment: If a regional rule can't be explained in one sentence beside the output, your implementation probably isn't transparent enough for users or support teams.
Designing for User Trust Through Validation and UI
Pretty interfaces do not create trust in a closing cost calculator. Traceability does.
In real estate, a taxes title and fees calculator is estimating charges that can change cash to close by thousands of dollars. Buyers, lenders, title teams, and agents do not need animation or clever copy. They need to see how the number was produced, which assumptions were applied, and where the estimate may still move before settlement.

Show the estimate as an auditable cost stack
A single total is convenient for demos and bad for production.
Enterprise-grade real estate calculators should present each estimate as a fee stack with enough context to survive scrutiny from a borrower, a support rep, or a compliance review. That usually means separating fixed government charges from title-related services, then isolating timing-sensitive prepaids and reserves that depend on close date, lender posture, and local practice.
A practical structure looks like this:
- Government charges: Transfer taxes, recording fees, mortgage-related filing charges, and other jurisdiction-driven items
- Title and settlement services: Title search, settlement or escrow fees, lender policy and owner policy estimates, and configurable provider charges
- Prepaids and reserves: Homeowners insurance, prepaid interest, tax escrows, and county-specific reserve assumptions
- Assumptions and caveats: Property location, transaction type, occupancy, financing details, rule version, and confidence level
That layout reduces support friction because disputes become specific. The conversation changes from "your calculator is wrong" to "why is the transfer tax applying in this county?"
Validation needs to happen before and after calculation
Input validation catches obvious failure states. Output validation protects the product from looking correct while being wrong.
For inputs, reject or quarantine records that would contaminate the estimate:
- Unresolved property identity: Address, parcel, or county cannot be matched with high confidence
- Contradictory transaction structure: Cash purchase paired with lender-only charges, refinance fields mixed into a sale flow, or invalid ownership scenarios
- Out-of-range financial values: Negative sale price, impossible loan-to-value combinations, or malformed dates that break proration logic
The second layer is where serious teams differentiate themselves. Validate outputs against signed closing disclosures, title invoices, and jurisdiction fee schedules. Build regression fixtures by county and transaction type. Store expected outputs with rule versions so a schedule update does not change production behavior without a review trail.
I have seen teams test the formula and skip the presentation layer. That is a mistake. If rounding rules, labels, or conditional disclosures drift from the underlying engine, users will treat a correct estimate as unreliable.
A trustworthy calculator gives users enough evidence to challenge the result line by line.
The interface should expose confidence, not hide uncertainty
Real estate estimates are rarely binary. Some fees are deterministic. Others depend on local title practices, lender instructions, recording counts, or the final closing date.
The UI should reflect that reality directly. Label fees as confirmed, estimated, or conditional. Show why a fee appears. Show what input would change it. If the engine had to fall back from parcel-level resolution to a broader geographic match, surface that with plain language instead of burying it in logs.
Teams building financial tools can borrow baseline readability principles from Figr's guide to user interface design, but a closing cost workflow has stricter requirements. Users need hierarchy, provenance, and controlled disclosure. Decorative polish matters less than making every number explainable.
A good front end should include:
| UI element | Why it matters | Bad alternative |
|---|---|---|
| Line-item breakdown | Makes disputes traceable to one fee or assumption | One lump-sum estimate |
| Editable scenario controls | Lets users test sale price, loan amount, or close date without restarting the flow | Full form resubmission for every change |
| Assumption labels | Explains why a charge fired and which rule produced it | Hidden defaults and silent rule application |
| Confidence and status indicators | Signals whether a figure is fixed, estimated, or conditional | Presenting every value as equally certain |
| Calculation timestamp and rule version | Gives support, ops, and compliance a shared reference point | No provenance |
If the interface still says "estimated closing costs" without a visible evidence trail, users are being asked to trust branding instead of system behavior. In real estate, that trust does not last.
Deployment Monitoring and Advanced Applications
Production failure in a closing cost calculator rarely looks like downtime. It looks like a plausible number that is wrong by enough to derail a transaction.
That changes how monitoring should be designed. Standard API uptime checks and generic error rates are necessary, but they do not protect the estimate itself. The system needs observability at the calculation level, because a real estate fee engine can return a structurally valid response while using stale transfer tax rules, an outdated recording fee table, or a fallback parcel match that shifted the jurisdiction.
Monitor every estimate request as a traceable financial event. At minimum, capture these signals:
- Input resolution status: whether the address was normalized, geocoded, and matched to a parcel or only to a broader geography
- Rule execution path: which county, city, loan, and title-related rules fired, and which assumptions were substituted
- Dependency health: whether tax, assessment, recording, or geocoding providers returned complete data or partial responses
- Confidence state: whether the output is based on direct source data, inferred values, or a manual override
- Escalation triggers: which scenarios should route to operations or support before a user relies on the result
Toy calculators fail at this level of detail. They log requests. Enterprise systems log why a fee appeared, which version of the rule produced it, and what degraded upstream data may have influenced the estimate.
Legal drift is the harder problem. Counties revise recording schedules. States change transfer tax treatment. Title fees vary by transaction type, financing structure, and local practice. A service can stay online for months while becoming less correct each week.
The fix is operational discipline:
- Version fee tables and jurisdiction rules
- Tie updates to named source documents or provider snapshots
- Run canary recalculations against benchmark properties and historical deals
- Alert on output deltas that exceed expected tolerance
- Keep rollback paths for bad rule deployments
For real estate products, the calculator should not live as a marketing widget bolted onto the website. It should sit in the same service layer that supports disclosures, underwriting, quote generation, and exception handling. That architectural choice matters because once multiple teams depend on the same engine, bad assumptions are exposed faster and fixed once instead of patched in four different tools.
The highest-value applications usually show up after launch:
| Advanced application | Why it matters |
|---|---|
| Seller net sheets | Converts closing cost logic into expected proceeds with clearer agent and consumer workflows |
| Portfolio underwriting | Applies consistent transaction cost assumptions across acquisition models and hold-sell analyses |
| AVM enrichment | Adds transaction friction and tax context to valuation workflows that otherwise stop at property value |
| Exception routing | Flags deals with unusual fee structures, missing source data, or low-confidence matches for human review |
I have seen teams underestimate this phase. They treat the calculator as a front-end feature, then later realize operations needs the same rule engine for internal quotes, support needs an audit trail for disputes, and data teams want bulk outputs for portfolio models. Rebuilding that after launch is expensive.
Build the engine once as shared infrastructure. Expose it through real-time APIs for consumer experiences and through batch workflows for underwriting, servicing, and acquisition pipelines. That is where a real estate taxes title and fees calculator stops being content and starts becoming part of the transaction stack.
If you're building a real estate taxes title and fees calculator that needs parcel-level context, assessment data, lien visibility, and bulk-ready APIs, BatchData is the kind of platform worth evaluating. It gives engineering teams access to large-scale U.S. property records, tax and assessment signals, and delivery options that fit both real-time products and portfolio workflows.