


































High latency in APIs can drive users away and cost businesses millions. For property search APIs, delays over 3 seconds lead to nearly half of users abandoning the service. Achieving response times under 100ms is critical for user retention and business success. Here’s what you need to know:
- Common Problems: Inefficient database queries, network overhead, and concurrency bottlenecks are the main culprits.
- Key Solutions: Use caching (e.g., Redis), optimize database indexing, implement asynchronous processing, and leverage load balancing.
- Real-Time Data: Streaming updates reduce delays and keep property listings current, improving user experience.
- Monitoring: Track P95 and P99 latencies to identify and fix performance issues.
Takeaway: Faster APIs mean better user retention and higher revenue. Focus on reducing latency through caching, database optimizations, and real-time updates for scalable, responsive systems.
How to Optimize API Performance for High-Traffic Applications | Keyhole Software
sbb-itb-8058745
Common Latency Issues in Scalable APIs
When it comes to real-time property searches, latency isn’t just a technical hiccup – it directly affects user experience. As property search APIs scale to handle thousands of simultaneous users, several bottlenecks can emerge, threatening responsiveness. Understanding these challenges is the first step toward creating systems that remain fast and reliable under heavy loads. Below, we dive into some of the most common latency culprits.
Inefficient Database Queries
One of the biggest performance killers is poorly optimized database queries. Missing or misconfigured indexes force the database to perform full table scans. While this might seem manageable in a small staging environment, it becomes a nightmare in production, where millions of records can turn milliseconds into seconds. Outdated query planners can make things worse, opting for inefficient strategies like nested loops over faster methods such as hash joins.
Optimizations like proper indexing and using connection pools can dramatically reduce query times. For example, optimized connection pools alone can slash transaction latency from 427 milliseconds to just 118 milliseconds – a reduction of nearly 85%. Without pooling, every API request triggers a new database handshake, which adds significant delay and can quickly exhaust available connections during traffic surges. A real-world example? In June 2025, Realie‘s Property Data API achieved sub-10 millisecond average latency by implementing advanced query routing and parallelized data fetching, outperforming the industry norm of 400–500 milliseconds.
"If I am buying APIs from someone and… the salesperson… talks about the ‘average’ latency, I know they are not serious about latencies there."
– Kushal Shah, Founder, Trestle
But database inefficiencies are only part of the story. Network overhead and external dependencies can also drag down performance.
Network Overhead and Data Enrichment Delays
Large JSON payloads can significantly slow down transmission and parsing. On top of that, APIs often rely on third-party services for tasks like geolocation, property insights, or payment processing. These external dependencies can become bottlenecks, as the overall latency is dictated by the slowest link in the chain.
For instance, Zillow tackled this issue in August 2022 by switching from fetching full "source" documents to using "doc values" in Elasticsearch. This adjustment reduced CPU usage by 38.7% and cut service latency by 11.5% at the 50th percentile and 25.6% at the 99th percentile.
"The physical location of the API client and server can contribute to an API’s latency because data transfer is not instantaneous. It is instead limited by the speed of light and the characteristics of the network infrastructure."
– The Postman Team
These examples highlight how both payload size and external dependencies can significantly impact API performance.
Concurrency and Synchronization Bottlenecks
Handling high levels of concurrency introduces another set of challenges. When CPU usage exceeds 80%, delays can grow exponentially due to queuing. Synchronous operations, which block threads, further exacerbate the problem by delaying other requests. During traffic spikes, this queuing effect can cause response times to jump from under 100 milliseconds to several seconds, potentially driving users away at crucial moments.
To remain competitive, property search APIs must address these bottlenecks head-on, ensuring they deliver the low-latency performance users expect.
Practical Solutions to Minimize Latency
Addressing latency bottlenecks requires targeted strategies that deliver consistent and efficient performance. Below are actionable techniques to tackle these issues and maintain a low-latency experience.
Implementing Caching Strategies
Caching is a game-changer when it comes to reducing latency. By storing frequently accessed data in memory, it eliminates repetitive database calls. Remote caching solutions like Redis ensure consistent responses across clients and allow for independent scaling, though they may introduce a slight network delay. Multi-level caching, which combines client-side and remote caching, strikes a balance between speed and data consistency.
For example, Zillow’s real-time recommendation service optimized its performance in August 2022 by utilizing Elasticsearch query caching. This approach achieved an impressive 63% cache hit rate by leveraging common UI filter values. Additionally, Kelsey Juraschka’s team reduced CPU usage by 38.7% and cut 99th percentile service latency by 25.6% by switching from fetching full "source" documents to using "doc values" in Elasticsearch.
"Storing data in a cache can improve read latency, read throughput, user experience, and overall efficiency, as well as reduce costs."
– AWS Well-Architected Framework
To maximize caching efficiency, aim for a cache hit rate of 80% or higher. Anything below this threshold may indicate issues like insufficient cache size or poor access patterns. Fine-tune Time-to-Live (TTL) settings to balance data freshness with backend load reduction. Additionally, pre-warming caches on secondary nodes using "Mirrored Reads" can help minimize performance dips during failovers.
While caching is essential, optimizing database operations is another critical step in reducing latency.
Optimizing Database and Indexing
Strategic database indexing can drastically improve query performance, cutting query times by up to 85%. APIs that filter by multiple criteria, such as city, price, and number of bedrooms, benefit significantly from composite indexes that cover all these fields. Regularly using tools like EXPLAIN ANALYZE helps identify inefficient sequential scans and replace them with faster index lookups.
Efficient connection pooling is equally important. Transaction-mode pooling, which releases connections immediately after each transaction, has been shown to reduce transaction times by 72%, dropping from 427 milliseconds to just 118 milliseconds.
For advanced property searches requiring similarity matching, tools like pgvector deliver sub-millisecond latency on complex queries. When working with massive datasets, partitioning by date or region can significantly reduce the amount of data scanned per query. Additionally, materialized views can pre-compute expensive aggregations, such as average prices per neighborhood, to avoid taxing real-time calculations.
| Query Type | Optimization Technique | Performance Impact |
|---|---|---|
| Text Search | Worker Threads (Redis) | Up to 1,478% increase in QPS |
| General Query | Strategic Indexing | 70–85% reduction in query time |
| Connection | Transaction-mode Pooling | 72% reduction in transaction time |
Asynchronous Processing and Load Balancing
Asynchronous processing helps offload time-intensive tasks from the main request-response cycle, keeping APIs responsive even under heavy load. Tools like Apache Kafka or RabbitMQ facilitate event-driven processing, allowing background workers to handle tasks, which reduces immediate strain on the API.
Load balancing is another essential strategy. It spreads incoming traffic across multiple backend instances, preventing any single node from becoming overwhelmed. Deploying stateless backends behind load balancers ensures automatic failover and scaling. In Kubernetes environments, Horizontal Pod Autoscalers (HPA) dynamically scale pods based on CPU or memory usage, eliminating the need for manual intervention.
For high-demand systems, techniques like Redis pipelining allow multiple commands to be executed simultaneously without waiting for individual responses. In benchmarks, pipelining improved data transfer speeds by a factor of five compared to non-pipelined requests.
"Pipelining is not just a way to reduce the latency cost associated with the round trip time, it actually greatly improves the number of operations you can perform per second in a given Redis server."
– Redis Docs
To safeguard against cascading failures, use circuit breakers with libraries like Polly or Hystrix. These tools can prevent system-wide disruptions when downstream services experience high latency. Additionally, configure health probes on load balancers to automatically redirect traffic away from struggling instances, maintaining consistent performance.
Real-Time Data Streaming for Improved Performance
Real-time data streaming directly addresses the delays caused by outdated information. By eliminating the lag inherent in batch updates or manual refreshes, this approach ensures users have instant access to the latest property listings. These systems tap into live databases that are continuously updated as new records come in, providing up-to-the-minute details on property availability, pricing changes, and listing updates.
Streaming Property Data Updates
Streaming data directly into cloud platforms like Snowflake or BigQuery removes the delays associated with traditional ETL processes. This ensures that analytics for high-traffic platforms remain current, a critical factor for industries where inventory changes frequently throughout the day.
The performance boost is massive – up to 60 times faster – because users no longer wait for updates to propagate. Instead, changes in property listings appear nearly instantaneously.
Switching to an event-driven architecture, such as using webhooks instead of constant polling, can cut server loads by 70–80%. Updates are pushed in real time whenever property details or prices change, reducing unnecessary API calls and keeping data fresh. This transition from a pull-based to a push-based model enhances efficiency and ensures users always see the most accurate information.
In-Flight Data Enrichment
Performing data transformations during request handling can further trim latency. Techniques like pipes or materialized views enable real-time enrichment as data flows in. For property search APIs, this might include tasks like verifying contact details, standardizing addresses, or providing property valuation estimates.
A well-planned setup is crucial. Dedicated Events APIs or Kafka connectors can stream JSON or NDJSON events from application frontends, ensuring low latency. Optimizing schema design is equally important – using column types such as Float64 for prices and DateTime for listing dates, along with smart sorting keys, can significantly improve query performance for location- and date-based searches.
To avoid redundant data transfers, include parameters like updated_at in queries to fetch only new or modified records. Pair this with Etag headers and If-None-Match requests to detect changes, reducing both bandwidth usage and processing demands.
These real-time upgrades lay the groundwork for the performance monitoring and benchmarking methods explored in the next section.
Monitoring and Benchmarking API Performance
API Latency Optimization Techniques: Performance Impact Comparison
When dealing with real-time streaming, monitoring becomes critical to identify delays that could disrupt the user experience. Averages alone don’t tell the full story – outliers often hide in the margins. That’s why tracking P95 and P99 latencies is so important. For instance, if your P99 latency is 800ms, it means 99% of requests are faster, but that remaining 1% could be waiting nearly a second or more. This kind of insight helps pinpoint where delays are impacting the slowest users the most.
Latency Measurement Tools
To accurately measure and diagnose API performance, tools like distributed tracing and API gateways (e.g., Apache APISIX) are indispensable. These tools automatically gather data on latency, error rates, and throughput across microservices and dependencies. This is especially crucial in complex systems, like property search platforms, where multiple data sources and enrichment services interact.
Pairing synthetic testing with real-user monitoring (RUM) provides a comprehensive view of API performance. Synthetic tests simulate user actions, such as property searches, across different locations and network conditions. This approach helps identify issues even during low-traffic periods. On the other hand, RUM captures live user interactions, uncovering performance gaps that synthetic tests might miss.
"We get Catchpoint alerts within seconds when a site is down. And we can, within three minutes, identify exactly where the issue is coming from and inform our customers and work with them."
– Martin Norato Auer, VP of CX Observability Services at SAP.
Performance Benchmarking and A/B Testing
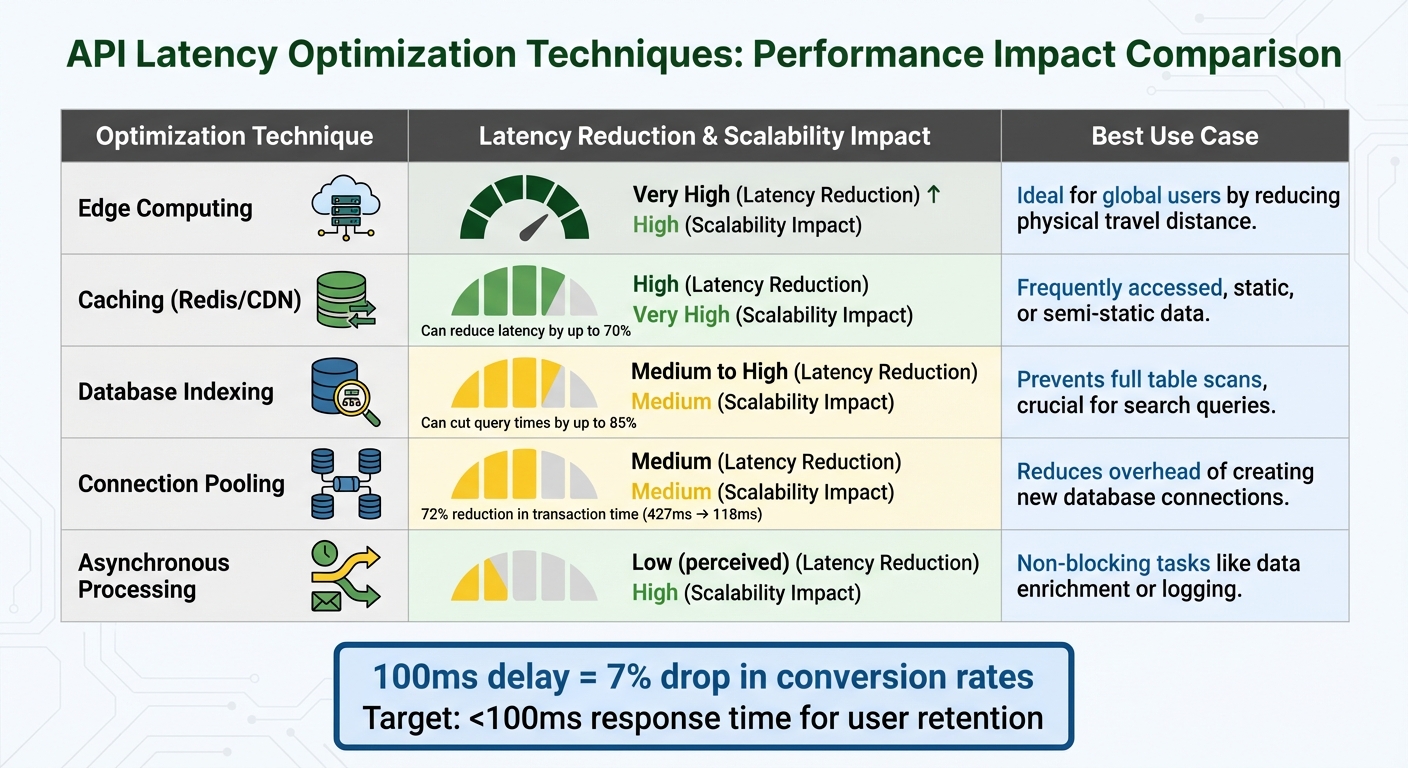
Benchmarking establishes a baseline for detecting performance regressions. For example, property search APIs are often tested to ensure that 95% of requests complete in under 200ms – a realistic target for real-time applications. Why does this matter? Even a 100-millisecond delay can lead to a 7% drop in conversion rates, making performance benchmarks a business necessity, not just a technical goal.
Canary deployments offer a smart way to validate changes by splitting traffic and testing improvements in a controlled, production-like environment. Integrating automated benchmarks into your CI/CD pipeline can help catch performance bottlenecks before they affect users. For instance, you could set alerts to notify your team if P99 latency exceeds 500ms for more than five minutes, preventing prolonged issues. These benchmarks also help guide decisions on which optimization strategies to implement.
Comparing Optimization Techniques
The effectiveness of optimization techniques often depends on your specific architecture. Here’s a quick breakdown of some common methods:
| Optimization Technique | Latency Reduction | Scalability Impact | Applicability |
|---|---|---|---|
| Edge Computing | Very High | High | Ideal for global users by reducing physical travel distance. |
| Caching (Redis/CDN) | High | Very High | Works well for frequently accessed, static, or semi-static data. |
| Database Indexing | Medium to High | Medium | Prevents full table scans, crucial for search queries. |
| Connection Pooling | Medium | Medium | Reduces the overhead of creating new database connections for each request. |
| Asynchronous Processing | Low (perceived) | High | Best for non-blocking tasks like data enrichment or logging. |
To maintain consistent performance, it’s essential to monitor resource usage – CPU, memory, and I/O. Systems nearing saturation often experience sharp increases in response times, making proactive monitoring key to avoiding disruptions.
Conclusion and Key Takeaways
Latency can seriously impact your conversion rates – and ultimately, your revenue. A delay as small as 100 milliseconds can reduce conversion rates by 7%. To keep users engaged, your APIs need to respond in under 100ms. Anything slower risks losing their attention.
Core Strategies for Low-Latency APIs
Reducing latency requires a combination of methods. Start by deploying regional endpoints and using tools like Redis or edge caching, which can cut latency by up to 70% and ensure property data loads almost instantly. Fine-tuning your database is just as important. For instance, switching from "source" to "doc values" in Elasticsearch can reduce service latency by 11.5% at the median and 25.6% at the 99th percentile.
You can also minimize latency by focusing on payload size and protocol efficiency. Replacing JSON with Protocol Buffers can shrink data size by 3–10 times, and implementing HTTP/2 or HTTP/3 eliminates redundant TCP handshakes. Connection pooling is another critical tactic, as it avoids the delays caused by opening a new database connection for every request. To truly understand user experience, track P95 and P99 latencies, which highlight the slowest interactions.
These technical improvements are even more effective when paired with dependable data sourcing.
The Role of Reliable Data Solutions
While technical fixes can lower latency, the consistency of your data sources plays a huge role in overall performance. Slow external providers can drag down your API’s speed. That’s where BatchData steps in. By focusing on geographic proximity and efficient data enrichment, BatchData optimizes backend infrastructure to deliver fast, reliable responses. Their property search APIs, contact enrichment tools, and bulk data delivery features ensure your applications get accurate, scalable property data – without backend delays. Considering that users perceive latency under 100ms as "perfect responsiveness", having a dependable data partner is critical.
FAQs
How does caching help reduce API latency?
Caching is a smart way to reduce API latency by temporarily storing frequently accessed data. This allows the system to fetch information quickly without needing to repeatedly query the database or external sources. The result? Response times can drop significantly – from hundreds of milliseconds to just a few milliseconds – offering users a faster and smoother experience.
With tools like Redis or Memcached, developers can define cache expiration rules (TTL) to keep data up-to-date while avoiding unnecessary database queries. For real-time property search APIs, caching does more than just boost speed and scalability; it also lowers server load and cuts down operational costs. This makes it a crucial approach for managing high volumes of requests effectively.
How does database indexing help reduce API latency?
Database indexing is key to reducing API latency by structuring data so the system can quickly find and fetch what it needs. Rather than combing through an entire table, the database relies on the index to jump straight to the data’s exact location, making queries much faster.
This is especially crucial for real-time property search APIs, where quick responses are essential for a smooth user experience. With the right indexing strategies in place, your API can maintain consistent performance, even as your data scales.
Why should you monitor P95 and P99 latencies for API performance?
Monitoring P95 and P99 latencies is crucial because they focus on the slowest response times users encounter, rather than just the average. P95 latency represents the time within which 95% of requests are completed, while P99 latency zeroes in on the slowest 1%. These metrics shine a light on outliers, often referred to as "tail" latencies, which can significantly affect user experience.
When P95 and P99 latencies are high, users may experience noticeable delays – especially in real-time or scalable APIs where consistent performance is key. By tracking these metrics, developers can identify bottlenecks, fine-tune system performance, and maintain API responsiveness, even during heavy traffic. This not only helps meet service level objectives (SLOs) but also boosts overall user satisfaction.


