


































Most real estate data problems come down to three things: too many systems, bad record matching, and weak controls. If I were setting up a hybrid cloud model, I’d keep sensitive data in tighter environments, push analytics and bulk processing to the cloud, and use a mix of batch files plus APIs based on how fast each workflow needs data.
Here’s the short version:
- I’d start with a full source inventory across MLS, county, title, CRM, property management, and warehouse systems.
- I’d sort each workflow by latency:
- Nightly batch for reporting and portfolio views
- 15 to 60 minute micro-batches for status changes and lead flow
- Under 5 seconds for lead routing, fraud checks, and phone or DNC checks
- I’d normalize core records around:
- property
- owner
- contact
- transaction
- valuation
- I’d standardize U.S. addresses with USPS Publication 28 rules and store money in U.S. dollars ($), dates in ISO-8601 for storage, and area in square feet or acres
- I’d lock down PII with role-based access, masking, tokenization, and field tagging
- I’d track pipeline health with row-count checks, schema drift alerts, and table freshness checks
- I’d measure results with hard numbers like:
- underwriting time
- lead match rate
- query latency
- data freshness
- cost per record
A simple rule runs through the whole setup: use bulk delivery for large datasets and real estate APIs for live lookups. That cuts manual work, keeps data more consistent, and helps new feeds plug in without forcing downstream teams to rework their tools.
| Area | What I’d focus on |
|---|---|
| Data sources | Internal systems, SaaS tools, and third-party feeds |
| Data movement | Batch ETL, micro-batch syncs, and REST API calls |
| Main risks | Duplicate records, stale contacts, schema drift, and PII exposure |
| Data standards | USPS address rules, county/APN alignment, fixed unit formats |
| Governance | RBAC, masking, tokenization, audit trails, and data cataloging |
| Performance | Partitioning by date/state/ZIP and clustering by county or property type |
| Success metrics | SLA hit rate, match rate, cost, latency, and analyst time saved |
If you want one takeaway, it’s this: a hybrid stack works when data placement, pipeline timing, record standards, and access rules are all set on purpose – not patched together later.
Hybrid Cloud Integration Patterns for Real Estate Data Pipelines
Ultimate Guide to Hybrid Cloud for Businesses
sbb-itb-8058745
2. Assess Your Data Sources, Requirements, and Gaps
Before you build any pipelines, take stock of every system that stores or moves your real estate data. Miss even one source, one owner, or one field definition, and the rest of the build starts to drag. This inventory sets the guardrails for architecture, freshness, and governance choices in the next step.
Map Internal and External Data Sources
Start with a simple catalog. For each system, note:
- System name
- Owner
- Deployment location: on-premises or cloud
- Data domains covered
- Connection method: ODBC/JDBC, SFTP, REST API, or message bus
- Update frequency
- Whether it contains sensitive data
Internal systems often include legacy SQL Server or Oracle databases that hold property master records and transaction history, plus appraisal and underwriting platforms, and ERP or accounting systems that track rent and capital expenditures.
Cloud and SaaS tools sit alongside them. That usually means CRM platforms like Salesforce for leads and ownership relationships, property management software for lease and tenant data, and cloud data warehouses like Snowflake or BigQuery.
Then there are external feeds, which add another layer. Common inputs include MLS/IDX feeds, county assessor and recorder bulk files, and parcel shapefiles. BatchData adds property and contact enrichment, skip tracing property owners, phone verification, address verification, and bulk delivery across the U.S. It also offers REST APIs for live lookups and direct delivery to Snowflake, BigQuery, or Databricks for bulk analytics.
Across all of these systems, map six core data domains: property attributes, ownership and contact data, transaction and deed history, lease records, valuation signals, and geospatial fields. For each domain, identify the authoritative source, secondary references, and downstream consumers. This isn’t a generic checklist. It’s the working map for your hybrid stack.
That matrix tends to expose duplication and gaps fast. It also gives you the basis for source-of-truth decisions in the architecture step. Use it to sort out which systems stay on-premises, which sync to the cloud, and which need to feed both.
Set Technical, Compliance, and Latency Requirements
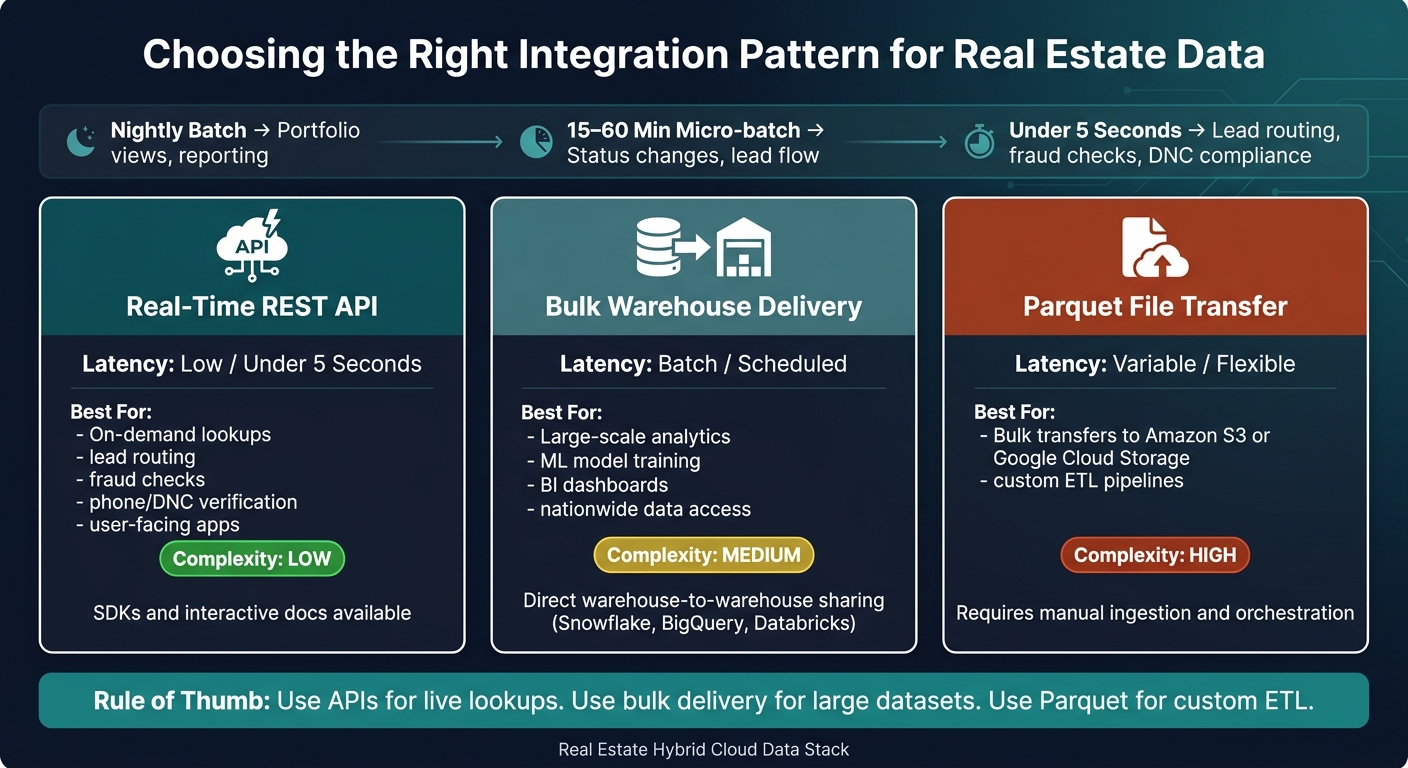
Not every workflow needs the same level of freshness. Some jobs are fine with nightly batch. That’s usually the right fit for portfolio valuation refreshes, occupancy dashboards, and rent roll consolidation.
Micro-batch, every 15 to 60 minutes, works better for process updates like new web leads moving into a CRM or listing status changes.
Near real time, under 5 seconds, is a different beast. You need that for lead routing, fraud checks, phone verification before outbound dialing, and DNC compliance checks.
For each workflow, document the required freshness, business hours, peak load, expected volume per run, acceptable lag during degraded operation, and the owner of the SLA. Put compliance rules in that same document too. Keeping them separate is asking for trouble.
Ownership and contact data often includes PII, such as names, phone numbers, and email addresses, governed by TCPA, CAN-SPAM, CCPA/CPRA, and similar state privacy laws. Tag every PII field. Define where that data can legally live. Set retention and deletion rules. And make sure outbound pipelines apply DNC suppression and TCPA consent flags before any enriched contact list reaches a dialer.
Document Data Quality Issues Before Integration
A data quality review done before pipeline work can save a lot of rework later. Check completeness first. Are owner name, mailing address, parcel ID, unit count, and lease dates filled in?
Then look at consistency. Are addresses USPS-standardized? Are dates in MM/DD/YYYY format? Is currency stored in USD with two decimal places? Is area measured in square feet?
Recency matters too. When were phone numbers, email addresses, and AVM estimates last verified?
The most common issues in U.S. real estate data are familiar ones: stale or missing owner contact fields, duplicate parcel records caused by inconsistent APNs across county sources, address format mismatches that block record linking, and misaligned FIPS and parcel IDs that break multi-market reporting.
Prioritize fixes based on business impact. DNC and compliance gaps carry the highest legal risk. After that, focus on entity resolution and verified contacts for revenue workflows. Then tackle address deduplication for day-to-day efficiency.
These gaps shape the standardization rules, matching logic, and enrichment priorities you build next.
3. Design the Hybrid Cloud Architecture and Integration Pattern
Once you’ve mapped your data inventory and logged the quality gaps, the next move is practical: decide where each dataset should live and how each system should connect. Those choices shape cost, latency, compliance, and how easy it will be to add new sources later. After that, match each workflow to the right transport pattern.
Choose Where Data Lives and How Systems Connect
A hybrid setup usually makes the most sense here. Keep sensitive systems on-premises or in a private cloud, and use the cloud for scalable storage, analytics, and enrichment. Platforms like Snowflake, BigQuery, and Databricks are well suited for large-scale analytics, while private systems continue to hold the original operational records.
For bulk transfers, send standardized data as Parquet files to cloud storage like Amazon S3 or Google Cloud Storage. That gives downstream teams a consistent format without forcing direct database access. For real-time record enrichment, use live APIs.
Pick the Right Pattern: Batch ETL, Streaming, or API Calls
Use the lightest pattern that still meets your freshness and volume needs. There’s no one-size-fits-all option for every real estate workflow.
| Integration Pattern | Latency | Best Use Case | Complexity |
|---|---|---|---|
| Real-Time REST API | Low | On-demand lookups, user-facing apps, live property details | Low (SDKs and interactive docs available) |
| Bulk Warehouse Delivery | Batch | Large-scale analytics, ML models, BI, nationwide data access | Medium (Direct warehouse-to-warehouse sharing) |
| Parquet File Transfer | Variable | Bulk transfers to Amazon S3 or Google Cloud Storage, custom ETL pipelines | High (Requires manual ingestion and orchestration) |
Use a REST API when a workflow needs the latest record-level data from systems that change all the time. Use bulk warehouse delivery when you need to train models, run BI queries, or share standardized datasets across teams. If you’re moving data in batches, Parquet files are a solid file-based handoff.
BatchData supports both patterns directly: a REST API for real-time transactional requests and direct delivery to Snowflake, BigQuery, or Databricks for bulk analytics workloads. That dual-track setup cuts down on custom ingestion work.
Model Core Real Estate Entities for U.S. Workflows
Once data movement is set, normalize the core entities every feed needs to share. In plain terms, define one schema that all feeds can map to. Property, owner, contact, transaction, and valuation entities should form the backbone of that model.
Property records should include APN, parcel ID, county FIPS code, square footage, acreage, and construction year. These identifiers act as the shared keys that line up assessor, MLS, and enrichment feeds. If you use geocodes, attach them directly to property records.
Ownership and contact records should clearly separate individual ownership from corporate ownership, especially when LLCs hide the actual decision-maker. Entity resolution matters here because it links records across owner portfolios. Contact records should also include verified phone numbers and email addresses, plus DNC and litigator status before anything flows into outreach systems.
Transaction and valuation records should store monetary values in USD and dates in MM/DD/YYYY format, with area measured in square feet or acres. Standard fields make it much easier for downstream systems to compare sales, tax, and valuation data without guesswork.
4. Build Pipelines, Standardization, and Governance
With your architecture set and your entity model ready, the next move is to make the stack work day to day. That means connecting systems, scheduling jobs, keeping formats consistent, and putting guardrails in place so teams can rely on the data they use.
Build Ingestion and Orchestration Workflows
Start by connecting on-premises systems to your cloud setup through secure paths like VPNs, private links, or managed agents. Tools such as Apache Airflow, AWS Glue, Azure Data Factory, or Prefect let you map each pipeline as a dependency graph, so jobs run in the right sequence and one failed source doesn’t knock over everything else.
For each source, keep the handoff path the same: on-prem source → secure connector → raw object storage → staging → curated layer. Raw data should land in object storage exactly as it arrived. From there, it gets light typing and cleanup in staging, then moves into the curated model after transformation and quality checks. Keep the raw layer unchanged for audits and reprocessing.
Run MLS snapshots overnight, outside peak usage hours. County assessor and recorder/title files usually arrive monthly or quarterly, so they should move through batch pipelines that can handle schema drift and support historical reprocessing. Use BatchData for bulk enrichment reloads or on-demand lookups during ingestion. Address verification should happen here, before records enter the curated layer, so bad data gets caught early and cleanup later is lighter. Make every job idempotent, market-specific, and safe to retry. Send malformed rows – like bad addresses or type mismatches – to a dead-letter queue instead of letting them block the full pipeline. Set SLA alerts so your team knows if a load misses its pre-business-hours SLA window.
Once ingestion is steady, you can enforce standardization and governance at each handoff.
Standardize Records for U.S. Real Estate Operations
After ingestion, normalize every record to one U.S. real estate schema.
This matters more than many teams expect. If one source says 123 Main Street Apt 5 and another says 123 Main St #5, those records may not match cleanly. Small formatting differences can create a big mess.
Apply USPS Publication 28 rules during transformation. Normalize street suffixes like "Street" to "ST" and "Avenue" to "AVE", directional prefixes like "North" to "N", and unit labels like "Apartment" to "APT". Break addresses into separate fields:
- street number
- pre-directional
- street name
- suffix
- unit type
- unit number
- city
- state using the 2-letter code
- ZIP
- ZIP+4 when available
CASS-certified tools can check addresses against USPS data and return deliverability status along with geocoordinates.
Use the same entity standards from the schema design phase in every pipeline stage: USD amounts, ISO-8601 storage, MM/DD/YYYY display, and square-foot/acres units.
Add Governance, Monitoring, and Role Ownership
Governance works best when it’s part of the pipeline from the start, not something added later. Define data domains such as property attributes, contact/owner PII, financials, and legal/title. Then assign minimum-necessary access by role right away.
Contact PII fields – names, phone numbers, email addresses, and mailing addresses – should live in restricted schemas with column-level security. Use dynamic masking for analyst roles and full tokenization for fields that should only be re-identified in tightly controlled workflows. Many warehouse-native controls can handle masking, tokenization, and role-based access.
Access control alone isn’t enough. You also need active monitoring. Row-count checks that flag deviations greater than ±10% from the prior load can catch bad imports fast. Schema drift detection should quarantine unexpected columns. Freshness checks on key tables like properties_current, active_listings, and contact PII tables help stop issues before they reach reports or apps. Keep a central data catalog that documents each dataset’s source, owner, PII classification, refresh frequency, and business description. That catalog becomes the go-to reference for audits, onboarding, and self-service analytics.
Assign a clear owner to each control. Here’s how the main responsibilities usually break down across a hybrid real estate data stack:
| Role | Primary Responsibility | Key Governance Task |
|---|---|---|
| Data Engineering | Pipeline integrity | Orchestration, row-count validation, ETL/ELT monitoring |
| IT / Security | Access control | API key management, RBAC, PII encryption |
| Analysts | Data quality | Validating AVM accuracy, monitoring attribute fill rates |
| Operations | Workflow integration | Ensuring standardized records align with CRM/ERP needs |
| Compliance | Audit and privacy | Masking PII, maintaining the catalog, enforcing U.S. privacy rules |
5. Optimize, Scale, and Measure Results
Improve Performance, Cost Control, and Enrichment Cycles
Use the monitoring from the governance layer to find the tables and jobs that need tuning. Large parcel, ownership, and transaction tables can get slow and expensive when you query them as one giant dataset. A better setup is to partition these tables by last_update_date, state, or ZIP code so each query scans only the rows it needs. Then cluster by county, property type, or price range to cut scan time even more. Keep raw and historical data in Parquet or ORC in the data lake, and publish only curated models to the warehouse.
It also helps to split workloads by what they need. Push compute-heavy work – AVM runs, portfolio stress tests, and geospatial joins – to the cloud. Keep latency-sensitive operational tasks, like CRM lookups, close to source systems. That split can cut query time and data transfer costs. On top of that, schedule heavy batch jobs during off-peak hours, auto-suspend idle compute clusters, and set per-team query quotas so one team doesn’t blow through the budget.
Once your core tables are running well, treat enrichment cadence as its own problem. Stale contact data ages out much faster than parcel history. Ownership records, phone numbers, and mailing addresses go bad faster than many teams assume. For lead generation, re-enrich absentee-owner contact data on a fixed cadence and flag stale records before outreach. For portfolio analysis, a slower refresh cycle may be enough.
Add New Feeds Without Breaking Existing Pipelines
New feeds – more MLS regions, zoning layers, updated valuation signals, or custom datasets – should plug into a stable integration layer that maps each source into your canonical schema. That keeps downstream tools like underwriting models, CRM systems, and dashboards from dealing with raw vendor formats directly.
Use versioned schemas to handle change without breaking things. If you need to add a new valuation field, introduce it as optional in a new schema version instead of changing existing fields in place. A schema registry can stop drift – unexpected columns, type changes, or dropped fields – before it hits production. For rollout, start with a single metro area, run parallel outputs next to the current pipeline, and compare lead match rate and AVM accuracy against the baseline. Expand into more markets only after quality and latency targets are met. This pilot rollout keeps disruption low and gives your team a clear rollback path if something fails.
Conclusion: Building a Hybrid Real Estate Data Stack That Works
A well-built hybrid real estate data stack follows a clear progression: assess your sources and gaps, choose the right integration pattern for each workload, standardize records to U.S. real estate schemas, enforce governance from the start, and keep tuning as volumes and business needs grow. Each step builds on the last. Clean ingestion makes standardization easier. Standardization makes governance more dependable. And governance gives you a way to measure optimization over time.
Measure the same pipeline you built, not a separate test copy. Track underwriting time, lead match rate, freshness, query latency, and cost per record before and after cutover. The goal is one governed stack that can take in new feeds without forcing downstream workflow changes.
FAQs
How do I decide what stays on-premises versus in the cloud?
Choose based on three things: how fast you need the data, how sensitive it is, and how much the workload swings.
Keep highly sensitive data or tightly controlled data on-premises when local control, strict access permissions, or zero internet reliance matter most.
Use the cloud when you need flexibility, remote access, and elastic scaling during listing surges or market spikes. A common hybrid setup works like this: real-time cloud processing handles immediate needs, while heavier batch refreshes run during off-peak hours to cut compute costs.
What is the best way to match duplicate property and owner records?
Use a strong entity resolution strategy at both the property and owner levels.
For properties, a simple three-step process works well:
- Exact match using the APN and a USPS-standardized address
- Geospatial proximity with near-exact address data when identifiers are missing or inconsistent
- Fuzzy matching to flag records for manual review
It also helps to normalize input data during ingestion. That includes things like addresses and APN formats. This step improves consistency and cuts down on duplicate records before they spread through the system.
How can I add new data feeds without breaking existing workflows?
Use modular mapping layers to translate each source schema into one unified internal model. That way, adding a new region or source feels more like a setup change than a big engineering project.
It also helps to standardize around a canonical property ID. Pair that with event-driven, asynchronous enrichment so new data connects cleanly, supports deduplication, and doesn’t slow down the main pipeline.


