


































Bad address data costs U.S. businesses over $20 billion annually. For real estate, the stakes are even higher – errors in address data can disrupt legal notices, skew property valuations, and waste marketing budgets. Address normalization and standardization are two key processes to fix this, but they serve different purposes:
- Normalization: Focuses on structure, ensuring consistency (e.g., "Street" → "ST").
- Standardization: Validates addresses against authoritative sources like USPS to confirm deliverability and accuracy.
Why does this matter? Address records degrade by over 2% per month due to changes like new developments or moves. Without regular upkeep, databases fill with errors, leading to missed opportunities and increased costs. Automating these processes can save teams 10–15% of their time spent on manual corrections.
Real estate platforms like BatchData use tools like CASS™ certification and Delivery Point Validation (DPV®) to ensure address accuracy. They handle bulk processing and maintain compliance with USPS standards, supporting precise property identification and reliable data for operations.
Key takeaways:
- Address components like ZIP+4, unit numbers, and directional indicators are critical for accuracy.
- Validation ensures addresses exist and are deliverable, reducing shipment failures and legal risks.
- Regular monitoring and deduplication prevent errors and maintain data quality.
Core Concepts in Address Data Normalization
How Addresses Move Through Real Estate APIs
When an address is processed through a real estate API, it typically goes through three key stages before becoming usable. First, the system captures the raw input – which often includes errors like typos and inconsistent abbreviations. Next, the address is standardized using CASS™ (Coding Accuracy Support System). This step ensures the address is formatted according to USPS guidelines, converting elements like "Street" into "ST" and applying other standardizations. Finally, Delivery Point Validation (DPV®) confirms whether the specific house or unit number exists in the USPS database.
Real estate platforms often store the raw input, the standardized version, and validation metadata (e.g., confidence scores). This layered approach helps prevent errors and ensures no critical details are overlooked. Skipping any of these steps could result in undetected inaccuracies. By understanding this process, you can better appreciate how individual address components are handled.
Key Address Components in the US
A properly normalized address in the US is more than just a street name and ZIP code. It’s a collection of specific components, each playing a distinct role in property identification, routing, and matching.
| Component | Example | Real Estate Relevance |
|---|---|---|
| Primary Street Number | 4821 | Anchors the property record |
| Street Name | Oak | Core identifier for matching |
| Street Suffix | AVE, ST, BLVD | Prevents duplicate record confusion |
| Directional (Pre/Post) | N, SW | Differentiates streets in grid-based cities |
| Unit/Sub-Premise | APT 3B, STE 200 | Essential for multifamily and commercial properties |
| City | Denver | Required for routing and geo-analytics |
| State | CO | Provides legal and jurisdictional context |
| ZIP+4 | 80203-1452 | Allows granular routing; updates monthly |
The sub-premise component – such as an apartment, suite, or unit number – is especially critical. Around 7% of addresses validate only at the building level when a specific unit number is necessary. For platforms managing multifamily housing or office spaces, capturing unit details should be treated as a core requirement, not an afterthought.
"In real estate, ‘deliverable’ is only the minimum bar. The true target is ‘safe to use as a property identifier.’" – BatchData
ZIP+4 codes are also worth noting. Unlike the standard 5-digit ZIP codes, the +4 extension corresponds to specific delivery routes and changes on a monthly basis. If your system treats ZIP+4 codes as static, it risks falling out of sync without regular updates. These components are essential for accurate address normalization, ensuring precise mapping within real estate APIs that transform business operations.
US Address Standards to Know
Once you understand the components, following USPS standards ensures the data remains reliable. The primary guideline for US address formatting is USPS Publication 28, which outlines the official abbreviations, formatting rules, and component order for all deliverable addresses. To meet these standards, CASS certification requires software tools to achieve at least 98.5% accuracy in standardizing addresses and assigning ZIP+4 codes. Additionally, the USPS mandates that the data used for this process must be no older than 105 days.
Beyond CASS, USPS provides supplementary systems to handle edge cases, which are particularly important for real estate:
- LACSLink®: Converts rural-style addresses (e.g., "RR 2 Box 14") into city-style formats, aiding rural property records and 911 updates.
- SuiteLink®: Adds missing suite or unit numbers to business addresses, improving deliverability for office complexes.
- NCOALink®: Matches address lists against the National Change of Address database. To comply with Move Update standards and qualify for postage discounts, mailing lists must be updated every 95 days.
"A standardized address is one that includes all required address elements and that uses the Postal Service standard abbreviations." – USPS
While USPS standards allow for both Proper Case and UPPERCASE formatting, maintaining consistency across your dataset is crucial. Inconsistent formatting is one of the top causes of failed deduplication, which can lead to significant downstream issues.
sbb-itb-8058745
Techniques for Address Standardization
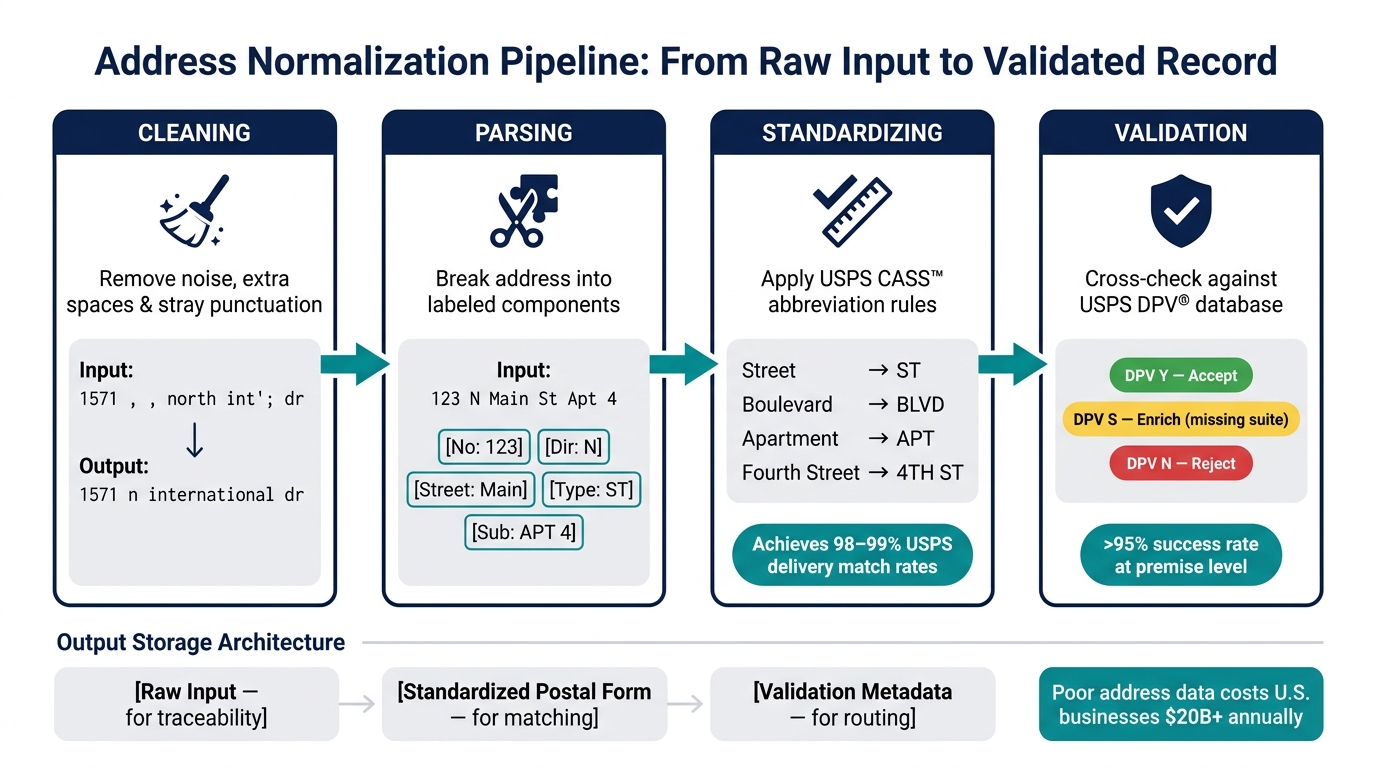
Address Normalization Pipeline: From Raw Input to Validated Record
Parsing and Structuring Address Data
In real estate APIs, breaking down raw address data into structured components is essential for maintaining accuracy and ensuring reliable validation. This process, known as parsing, takes an unstructured address like "123 N Main St Apt 4" and splits it into labeled parts: house number (123), directional (N), street name (Main), suffix (ST), and sub-premise (APT 4).
There are two primary methods for parsing:
- Rule-based parsing: Uses regular expressions to match known address patterns.
- Probabilistic parsing: Leverages libraries that can interpret ambiguous strings by weighing multiple possibilities.
Before parsing begins, it’s crucial to clean the input. This means removing extra spaces, stray punctuation, and normalizing the text. For example, "1571 , , north int'; dr" would first be cleaned to "1571 n international dr".
Here’s how the process transforms an address step by step:
| Step | Action | Example Transformation |
|---|---|---|
| Cleaning | Removes noise | "1571 , , north int'; dr" → "1571 n international dr" |
| Parsing | Breaks into components | "123 N Main St" → {No: 123, Dir: N, Street: Main, Type: St} |
| Standardizing | Converts to USPS abbreviations | "Apartment" → "APT"; "New York" → "NY" |
| Validation | Confirms against reference data | Verifies "123 N Main St" exists in USPS or county records |
Once parsed, the components are ready for standardization according to USPS guidelines.
Standardizing Address Formats
After parsing, the next step is to ensure each component follows USPS formatting rules. This involves replacing full terms with standardized abbreviations (e.g., "Street" becomes "ST", "Boulevard" becomes "BLVD", and "Fourth Street" becomes "4TH ST"), removing unnecessary punctuation, and unifying casing to either UPPERCASE or Proper Case. Adding the ZIP+4 code further improves compliance and precision.
"Any address standardization software must be CASS certified (Coding Accuracy Support System)." – Placekey
Manual standardization is not practical at scale – it’s time-consuming and prone to errors. Instead, automated systems equipped with CASS-certified tools handle these tasks efficiently, achieving 98–99% USPS delivery match rates.
Once the addresses are standardized, they are ready for validation against authoritative databases.
Validating Addresses with Reference Data
Standardizing an address ensures it’s in the correct format, but it doesn’t confirm the address exists. Validation involves cross-checking the formatted address against trusted datasets, like the USPS database, to confirm deliverability and identify potential issues. This step is crucial for accurate property identification and dependable service delivery in real estate workflows.
When working with validation APIs, pay attention to fields like validationGranularity. An address validated only at the street level is less reliable than one confirmed at the premise level, especially for critical real estate operations. Advanced validation APIs boast success rates exceeding 95% for complete US addresses at the premise level.
For cases where input data lacks details – like an apartment or suite number in a multi-unit building – flagging the record for manual review is a better choice than automatic acceptance. Around 3% of addresses pass standard validation but still lack essential sub-premise information.
Additionally, over 15 million US addresses appear in county records but are missing from USPS datasets. These are often properties in rural or remote areas with low mail volume. Real estate platforms focusing on these markets can bridge this gap by supplementing USPS validation with county parcel data to maintain accurate and comprehensive property records.
"A bad address is not a formatting problem. It is an underwriting problem, a servicing problem, and a lead quality problem." – BatchData
Error Handling and Deduplication
Effective error handling and deduplication are crucial steps in ensuring that only accurate and reliable address data moves through the system. These processes build on parsing and validation techniques to maintain data integrity.
Common Address Data Errors
Even after parsing and standardization, address datasets often contain errors that can compromise their quality. Common issues include formatting discrepancies like "MAIN ST" versus "Main St", incomplete entries missing ZIP codes or state details, and data entry mistakes such as typos or jumbled single-line inputs.
Beyond these, two less obvious but equally problematic errors are ambiguous locations and inaccurate jurisdictions. For instance, a ZIP code that spans multiple counties might incorrectly assign a property to the wrong tax authority. Similarly, addresses in unincorporated areas often use a mailing city name that doesn’t align with the legal county – a critical distinction for real estate underwriting and title work.
Here’s a breakdown of typical errors and how they’re identified:
| Error Category | Specific Example | Identification Technique |
|---|---|---|
| Duplicate Records | "123 Main St" vs. "123 Main Street" | SQL DISTINCT or GROUP BY |
| Phonetic Typos | "Marsel" vs. "Marseille" | DIFFERENCE() function |
| Spelling Typos | "Amphtheatre" vs. "Amphitheatre" | LEVENSHTEIN() distance |
| Missing Data | Null ZIP code or state | IS NULL query |
| Boundary Errors | Properties spanning county lines | Parcel-level reverse geocoding |
If these issues aren’t addressed, they can snowball across systems, reducing match rates, distorting geo-analytics, and increasing risks in underwriting and title workflows. For example, it’s essential to flag PO Boxes and Commercial Mail Receiving Agencies (CMRAs) during ingestion since they do not represent taxable physical properties and should be treated separately.
Data Cleansing and Fuzzy Matching
Before diving into matching logic, it’s important to clean the data. SQL functions like TRIM() remove stray spaces, while INITCAP()/UPPER() and REGEXP_REPLACE() handle casing inconsistencies and abbreviation corrections across entire columns.
Once the data is prepped, fuzzy matching tackles more nuanced discrepancies – like typos or phonetic differences. The DIFFERENCE() function scores phonetic similarity on a 0–4 scale, and LEVENSHTEIN() measures the number of edits needed to align two strings, making it useful for spotting transposed or missing characters.
"Address standardization corrects errors, fills in missing parts, and structures each record into a predictable format… The result is data you can trust and reuse across systems." – Geoapify
Many real estate APIs provide a confidence score (ranging from 0.0 to 1.0), which helps automate decision-making. For example, you can set a threshold (like 0.9 or higher) to automatically approve clean matches while flagging lower-confidence records for manual review. Always test your cleansing scripts on a small subset before scaling up, and back up the original data to safeguard against errors.
Deduplication and Canonical Records
Once the data is clean and matched, deduplication ensures the dataset includes only one canonical record per property. However, this process hinges on normalization – standardizing formats like "123 Main St" and "123 Main Street" before comparing them ensures accurate matches.
For tasks requiring county-level precision, rely on FIPS codes (five-digit Federal Information Processing Standard identifiers) instead of county names. This eliminates confusion caused by duplicate names, such as the 30 "Washington Counties" across the United States.
For properties that cross county lines, parcel-level geocoding is a more reliable method than postal lookups. Using the centroid of a building footprint ensures accurate identification of the situs county – the legal jurisdiction where the property’s main structure is located. This is essential for tax records, title searches, and lien data.
Platforms like BatchData incorporate these practices into their real estate API solutions, delivering high-quality address data to support informed decision-making.
Implementing Normalization in Real Estate APIs
Normalization in ETL and Streaming Pipelines
Position address normalization as a dedicated service layer between your intake channels and downstream systems. This ensures every address is cleaned and validated before interacting with critical systems.
Deciding between real-time or batch processing depends on how and where data enters your system:
| Attribute | Real-Time API | Batch Processing |
|---|---|---|
| Primary Use | Point-of-entry (forms, CRM) | Cleansing large datasets |
| Data Flow | Synchronous; instant response | Asynchronous; file-based |
| User Experience | High; immediate feedback | Low; background process |
| Technical Skill | Requires developer integration | Minimal; simple file uploads |
This structured approach helps in designing APIs capable of handling normalized addresses effectively.
For storage, a three-tier schema works best: raw input for traceability, standardized postal form for matching, and validation metadata for routing. This setup lets you audit, reprocess, and maintain quality assurance without losing the original data.
"Static address tables don’t just get old. They actively create false negatives when geography changes." – Ivo Draginov, Author, BatchData
Implement fallback logic to address issues like validation provider timeouts or weak coverage in specific regions. In such cases, the system should gracefully switch to alternative methods, such as postal-code-plus-locality validation, or route the record to manual review.
Designing APIs for Normalized Address Handling
Real estate APIs should accommodate both unstructured (single-line) and structured (separate fields) inputs to cover the variety of sources you’ll encounter.
On the output side, simply returning a formatted address string isn’t enough. Include additional data points like verdict (accept/fix/confirm), validationGranularity (e.g., premise or street level), and addressComplete status in every response. These signals can streamline automated routing and reduce manual work.
Here are a few design rules to follow:
- Never expose API keys in frontend code. Use server-side proxies and environment variables to handle requests, enabling centralized rate limiting and logging.
- Flag missing sub-premise data. If input for a multi-unit building lacks suite or apartment numbers, trigger a prompt instead of letting the record pass unnoticed.
- Account for retention limits. Some APIs restrict storing validated results beyond 30 days. This may require re-validation or using a hybrid model with a property data platform like BatchData for long-term storage.
"In real estate, ‘deliverable’ is only the minimum bar. The true target is ‘safe to use as a property identifier.’" – Google Validate Address: Proptech API Guide
These principles align smoothly with monitoring strategies to maintain data quality.
Monitoring and Quality Assurance
Building on ETL and API design practices, monitoring ensures compliance with USPS guidelines and Delivery Point Validation (DPV®) metrics. CASS™-certified software must achieve at least 98.5% accuracy when standardizing addresses and assigning ZIP+4 codes.
DPV goes further by confirming whether a specific house or unit number exists, not just whether it falls within a valid range. Use DPV response codes as actionable signals: a "DPV N" result indicates the address is invalid and should be rejected outright, while a "DPV S" result – valid primary address but missing suite data – requires enrichment or manual review.
"An address is not ‘good’ data until the USPS confirms it’s a real place they deliver to. Without this programmatic check against the source of truth, you are guessing." – BatchData
For fuzzy matching, auto-accept matches with confidence scores above 95%, and flag those between 70–94% for manual review. Integrating normalization outputs with tools like Tableau or Power BI can help identify geographic clusters of poor data quality before they disrupt workflows. Since the USPS updates its reference database monthly, set up regular re-validation cycles to ensure your address records stay current.
Conclusion
Address normalization isn’t a one-and-done task – it’s an ongoing process that keeps real estate operations running smoothly. By parsing addresses, aligning them with USPS standards, validating them against trusted reference data, removing duplicates, and storing them as canonical records, you create a reliable foundation. This foundation acts as a primary key that links property data, ownership history, valuations, and contact details across all your systems. It’s a critical step in preparing for the challenges ahead.
The business case for this is clear. Poor address quality can snowball into bigger problems: undeliverable mail wastes marketing budgets, analytics become skewed when the same property is listed in multiple formats, and field teams risk being sent to incorrect locations. A 2019 Experian survey revealed that organizations estimate 29% of their customer and prospect data is inaccurate. Addressing these issues at the point of ingestion is far more cost-effective than fixing them later.
A repeatable pipeline – consisting of steps like ingesting, parsing, standardizing, validating, matching, deduplicating, and monitoring – ensures your data remains consistent and compatible with MLS feeds, county assessor records, lenders, and third-party APIs. Using tools like ZIP+4 codes, two-letter state abbreviations (e.g., CA, TX, NY), and USPS street suffixes (ST, AVE, BLVD) guarantees this compatibility.
Scalability is the next piece of the puzzle. Platforms such as BatchData streamline the process, automating enrichment and maintenance tasks. These tools handle bulk normalization projects and ongoing updates, sparing your team from tracking USPS changes or shifts in municipal boundaries.
To move forward, start by auditing your data. Look at duplicate rates, missing ZIP+4 codes, and geocoding match rates. These metrics will highlight gaps that drive up costs and help you determine your next steps.
FAQs
When should I validate an address versus just normalize it?
When precision matters – be it for legal purposes, shipping logistics, or regulatory compliance – address validation becomes a crucial step. This process ensures that the address is accurate and functions as intended, reducing errors and potential complications.
On the other hand, address normalization focuses on standardizing address formats. By converting varied address inputs into a consistent structure, normalization helps maintain uniformity in databases and simplifies operations. Together, these practices enhance data reliability and operational efficiency.
How do I handle missing apartment or suite numbers in multi-unit buildings?
When dealing with missing apartment or suite numbers, it’s essential to use standardized address formats that incorporate unit identifiers for better clarity and consistency. If the unit number is missing, you can try appending it based on available property records or reaching out to the property manager for confirmation. Address standardization tools can also assist in correcting or adding these missing details, ensuring greater accuracy and smoother operations for real estate and mailing purposes.
How often should I re-validate addresses to keep ZIP+4 and DPV results current?
To keep your address data accurate and reliable, it’s a good idea to re-validate addresses regularly. This includes checking details like ZIP+4 codes and Delivery Point Validation (DPV) results. Experts often recommend updating this information every 6 to 12 months or whenever there are changes to the address data to maintain consistency and avoid delivery issues.


