


































Property tax data in the U.S. is vast but fragmented, with over 3,200 counties using inconsistent formats, field names, and update schedules. Standardizing this data is crucial for real estate workflows like mortgage underwriting, property valuations, and investment analysis. A unified approach simplifies integration, improves accuracy, and enables faster access to data.
Key Takeaways:
- Challenges: Data fragmentation across counties, inconsistent field names (e.g.,
APN,parcel_id), and varying update schedules. - Solution: Create a standardized schema with core fields such as APN, assessed value, tax year, and property characteristics.
- Benefits: Faster workflows, reduced errors, and seamless integration of data from 155+ million U.S. properties.
- Steps:
- Define a canonical schema with clear data types and constraints.
- Build a pipeline to ingest, map, normalize, and validate data.
- Design API endpoints for property-specific lookups and tax-centric queries using an ultimate guide to real estate APIs.
- Implement quality checks for completeness, accuracy, and timeliness.
- Enrich tax data with additional layers like geolocation and market signals.
This guide explains how to streamline fragmented tax data into an API-ready format, ensuring consistency and reliability across jurisdictions.
Understanding the U.S. Tax Data Landscape
Where Tax Data Comes From
Property tax data comes from a variety of sources, each with its own strengths and challenges. County assessor and recorder offices serve as the primary providers of tax and ownership data. These offices operate independently across more than 3,200 jurisdictions in the U.S., making their data highly authoritative but often inconsistent in format and update frequency.
In some states, like Massachusetts and Washington, centralized repositories streamline the process by standardizing field names and linking assessor records to geographic data. This ensures a single, cohesive mapping between tax records and geographic boundaries. However, such systems are not available nationwide.
Commercial aggregators play a critical role by gathering, cleaning, and normalizing data from all these local sources. They provide nationwide coverage in formats ready for integration via APIs. For example, BatchData combines input from over 3,200 sources to maintain a steady and reliable data flow, even during county-level outages:
"Our blended intake from over 3,200 sources mitigates county outages, ensuring a continuous and reliable data flow." – BatchData
Here’s a quick breakdown of the key sources:
| Source Type | Primary Strength | Primary Weakness |
|---|---|---|
| County Assessors | Accurate for tax liability and ownership records | Fragmented formats; irregular update schedules |
| State Repositories | Standardized fields within the state | Limited to certain states |
| Commercial Aggregators | Nationwide coverage, API-ready data | Licensing costs; slight delay from original data |
By understanding these sources, it becomes clear how standardized data can transform real estate workflows.
Key Use Cases for Standardized Tax Data
Standardized tax data is a game-changer for many real estate processes. In mortgage and lending, underwriters can instantly verify ownership details and access valuation history without manually sifting through county records. For real estate platforms, this data enriches property listings with official assessed values and tax amounts directly from assessor records. Similarly, insurance companies use detailed property characteristics – such as square footage, construction type, and year built – to model risk efficiently at scale.
Investment analysts also benefit by identifying trends in tax assessments. For instance, they can spot undervalued markets or properties where assessed values lag behind market prices. Interestingly, a 1% increase in market value typically results in less than a 0.30% rise in assessed values over the next three years. This means assessed data often underrepresents true market exposure. Legal and title professionals also rely on this data during due diligence, enabling them to verify parcel boundaries and legal descriptions in seconds rather than days.
These use cases highlight the critical role of standardized tax data in improving efficiency and accuracy across the real estate sector.
Defining a Minimum Viable Tax Schema
To make the most of tax data, it’s essential to establish a minimum viable schema that unifies key attributes. Before creating any pipeline or API endpoint, you need to identify the most important fields. A practical schema typically includes five core categories:
- Identifiers: Assessor Parcel Number (APN), FIPS code (a combination of state and county identifiers), and a stable UUID for tracking across providers.
- Location data: Situs (property) address, latitude/longitude coordinates, and legal description.
- Assessment attributes: Land value, building (improvement) value, and total assessed value.
- Tax attributes: Annual tax amount, tax year, applicable tax code area, and exemption flags (e.g., Homestead exemptions).
- Property characteristics: Building square footage, year built, number of bedrooms and bathrooms, lot size, and land use code.
One particularly important element is the FIPS code. It ensures uniqueness by preventing parcel ID conflicts when the same APN format is used in multiple counties. By pairing each apn with its corresponding fips code, you create a composite key that remains unique across all 3,200+ jurisdictions. This schema provides a solid foundation for integrating additional data layers down the line.
sbb-itb-8058745
How to Design a Standardized Tax Schema for Real Estate APIs
Steps to Build a Canonical Schema
Creating a unified schema for real estate tax data involves addressing a key challenge: different counties often use inconsistent field names for the same data. For instance, one county might refer to a parcel number as "APN", another as "PIN", and yet another as "AIN." The solution? Consolidate these variations into a single, standardized structure.
Start by grouping fields into logical categories such as identification, valuation, taxation, ownership, physical characteristics, and location. Once these categories are defined, map all local field variants to their corresponding standardized fields. For any data that doesn’t fit into these groups, include an unmapped JSON object. Additionally, store both the raw parcel ID and a cleaned version (removing spaces and dashes) to maintain consistency.
After mapping the fields, the next step is to define clear data types and constraints to ensure reliable data handling.
Data Types, Standards, and Constraints
Using incorrect data types can cause serious issues. For example, storing a tax amount as a string instead of a decimal could disrupt calculations. The Real Estate Standards Organization (RESO) highlights the importance of matching payload data to metadata:
"Payload data should match what is in the metadata, including things like data types, lookups, date and time formatting, string lengths, and decimal precision." – RESO Data Dictionary 2.0 Release Guide
To avoid problems, assign appropriate data types to each field:
- Use
doubleorNUMERICfor financial data like assessed land value and tax amounts. - Use
INT64for whole numbers like tax year or bedroom count. - Use
DATEfor dates, such as sale or assessment dates. - Use
STRINGfor identifiers like FIPS codes and APNs. Treat FIPS codes as strings to preserve leading zeros (e.g., Alabama’s FIPS code starts with "01").
For categorical fields – such as property type, tax status, or exemption type – enforce strict enumerations. For instance, map local terms like "Homestead Exempt" or "HS" to a standardized value like homestead. This ensures consistency for cross-county analysis.
Here’s a summary of essential fields by logical grouping:
| Logical Grouping | Essential Fields | Data Type |
|---|---|---|
| Identification | APN, FIPS Code, UUID, Account Number | STRING / UUID |
| Valuation | Assessed Land Value, Improvement Value, Total Assessed Value | NUMERIC / DOUBLE |
| Taxation | Tax Amount, Tax Year, Tax Status, Delinquent Year | DOUBLE / STRING |
| Ownership | Owner Name, Vesting Type, Exemption Flags | STRING / BOOLEAN |
| Physical | Year Built, Building SqFt, Lot SqFt, Bed/Bath Count | INTEGER / DECIMAL |
| Location | Situs Address, Lat/Lon, Census Tract, Zoning Code | STRING / NUMERIC |
One tricky aspect is the definition of building area, which varies by county. Some report "living area", while others use "gross area." Instead of picking one standard, include a companion field like area_building_definition to clarify the measurement method used.
Once these data types and constraints are defined, documenting the schema is crucial for clarity and consistency.
Documenting the Schema with OpenAPI
A schema is only effective if developers can quickly understand and use it. OpenAPI (commonly documented via Swagger) provides a framework to define each field’s data type, constraints, and description in a machine-readable format. This format can also auto-generate interactive documentation for developers.
A standardized schema not only integrates diverse property data sources but also supports scalable real estate API development. Each API endpoint should reference a shared schema component, such as a TaxRecord object, ensuring consistent changes across endpoints. Include clear descriptions for each field to explain its purpose. For example, the taxyear field should specify that it represents the year the assessment was levied – not necessarily the year the taxes were paid. Providing this level of detail reduces confusion, minimizes support requests, and speeds up developer adoption.
Building a Tax Data Standardization Pipeline
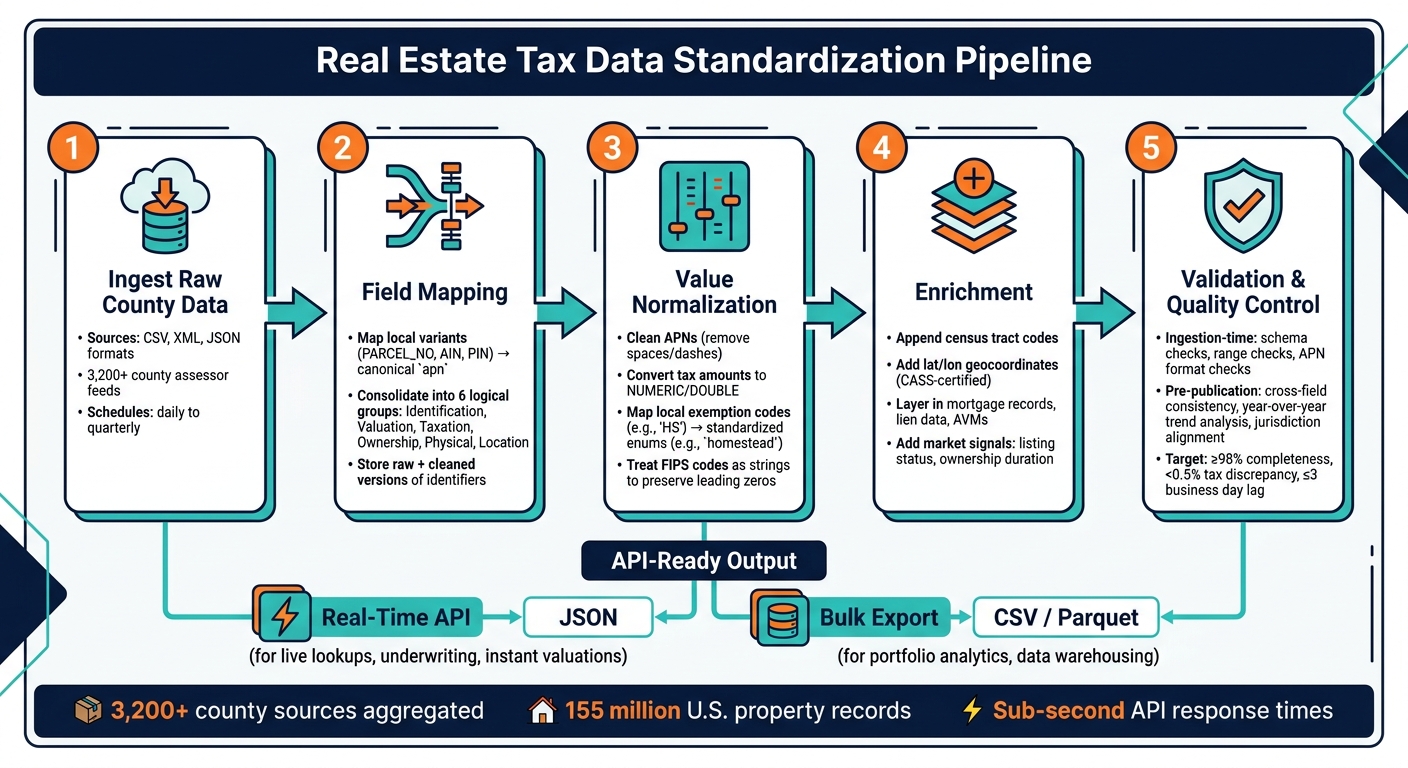
How to Standardize Real Estate Tax Data for APIs: 5-Step Pipeline
This section outlines the steps needed to convert raw county tax data into standardized, API-ready information, building on the canonical schema discussed earlier.
Ingesting and Parsing Raw Tax Data
County assessor offices provide tax data in various formats like CSV, XML, and JSON, with update schedules that range from daily to quarterly. The ingestion layer must be flexible enough to handle these differences without causing issues for downstream processes.
The production pipeline aggregates data from thousands of county sources simultaneously. This design ensures the pipeline remains operational even if a single county’s feed goes offline. After ingestion, the next step is transforming this diverse input into a unified format.
Transforming Data into a Standardized Format
After ingestion, raw tax data undergoes four key steps to ensure consistency: field mapping, value normalization, enrichment, and validation.
- Field Mapping: Converts county-specific fields like
PARCEL_NOorAINinto the canonicalapnfield. - Value Normalization: Cleans up identifiers, converts tax amounts into numeric formats, and maps local exemption codes (e.g., "HS") into standardized enums like
homestead. - Enrichment: Fills in missing details using public data sources, such as adding census tract codes or geolocation coordinates.
- Validation: Ensures data accuracy through automated tests and manual reviews for complex edge cases that automation might miss.
This layered approach to quality control minimizes errors and ensures the data is accurate before it reaches the production API.
Designing API Endpoints for Tax Data
With standardized data ready, the next step is to design efficient API endpoints. A good tax data API separates two main use cases: property-specific lookups and tax-centric queries.
- A property-focused endpoint like
GET /properties/{apn}/taxretrieves the full tax record for a specific parcel. - A tax-centric endpoint such as
GET /taxes?fips=06037&tax_year=2024&status=delinquentallows developers to query tax data across jurisdictions by attributes like year or delinquency status.
This separation keeps the API intuitive and avoids unnecessary data fetching.
Modern tax data APIs are designed for high performance, offering sub-second response times for RESTful JSON calls and maintaining 99.99% uptime SLAs. To meet different use cases, the pipeline can output data in multiple formats: JSON for real-time API needs and Parquet or CSV for bulk historical data delivered via SFTP. This flexibility ensures both real-time applications and data science teams can work with the same dataset without competing for resources.
Maintaining Tax Data Quality and Governance
Once you’ve standardized tax data for API consumers, keeping it accurate and up-to-date becomes a top priority. According to a Gartner analysis, poor data quality costs organizations an average of $12.9 million annually. Real estate tax data, pulled from over 3,000 counties – each with its own systems and update schedules – is particularly prone to quality issues.
Key Data Quality Dimensions
To ensure your tax data is reliable, focus on these four critical dimensions: completeness, accuracy, timeliness, and consistency.
- Completeness: Every parcel record should include all essential fields, such as assessed value, tax year, tax authority, exemptions, and payment status. Aim for ≥ 98% record completeness, including at least three years of tax history.
- Accuracy: Your records should closely match official county data. A good benchmark is less than 0.5% discrepancy in total tax due when sampled against authoritative sources.
- Timeliness: Minimize delays between when counties update their data and when your system reflects those changes. A target of ≤ 3 business days for supported feeds is achievable with direct county integrations.
- Consistency: Ensure uniformity in field names, data types, and code lists across all jurisdictions. For example, a
homesteadexemption in Texas should align with the same exemption in Florida under your schema.
Define measurable KPIs for these dimensions and use dashboards and automated alerts to detect quality issues before they impact API consumers. These metrics form the foundation for effective validation processes.
Implementing Validation and Testing
Validation should occur at two key stages:
- Ingestion Time: Run quick checks as data enters your system. These include:
- Schema validation (e.g., required fields, correct data types, permitted enum values).
- Range checks (e.g., tax amounts must be non-negative,
tax_yearshould fall within a valid range like the past 10 years through the next year). - Identifier sanity checks (e.g., APN formats should match the expected county pattern).
Flag any records that fail these checks with error codes for further review.
- Pre-Publication: After transforming data into your canonical schema, perform more detailed checks:
- Cross-field consistency tests (e.g., do line-item taxes add up to
total_taxwithin a $1.00 margin?). - Year-over-year trend analysis (e.g., a sudden 10x increase in assessed value without a reassessment event should trigger an alert).
- Jurisdiction alignment checks (e.g., does the tax authority code match the parcel’s county boundary?).
- Cross-field consistency tests (e.g., do line-item taxes add up to
These checks should be integrated into your CI/CD pipeline as version-controlled test suites. This way, onboarding new counties or modifying schemas automatically triggers validation processes.
Governance and Security Best Practices
Effective governance begins with clear roles and responsibilities. Assign a data owner to oversee overall tax data quality and data stewards to handle day-to-day operations. Establish escalation paths for resolving issues quickly. Maintain a data catalog that documents each field and ensures every tax value is traceable back to its original source for auditing and debugging.
On the security side, deliver data through RESTful APIs with developer-specific keys for real-time access or SFTP for bulk extracts. Encrypt data both in transit and at rest. Since tax records often include sensitive information like owner names and mailing addresses, enforce strict access controls and comply with relevant privacy laws such as CCPA/CPRA. Use schema and snapshot versioning to create a stable, auditable governance model that API consumers can trust for consistent and reliable data slices.
Advanced Use Cases for Standardized Tax Data
Having a standardized and dependable tax data pipeline opens the door to a range of advanced applications for real estate professionals. This isn’t just about organizing data – it’s about creating opportunities for deeper analytics, smarter enrichment, and streamlined automation that fragmented county data simply can’t support.
Analytics and Insights You Can Build
Standardizing over 10,000 local land use codes allows for consistent comparisons across states. This enables real estate professionals to dive into key analyses like effective tax rates, tax appeal leads, and long-term valuation trends – tools that can transform workflows across jurisdictions:
- Effective Tax Rate Analysis: By comparing
total_taxwithtotal_assessed_value, you can identify areas where tax burdens are outpacing property value growth. This insight is invaluable for managing portfolio risks. - Tax Appeal Lead Generation: Properties with unusually high assessed values per square foot compared to similar neighboring parcels can be flagged for potential tax appeals. This process becomes feasible only with a consistent data schema.
- Long-Term Valuation Trends: With up to 15 years of historical assessment data, you can uncover cyclical valuation patterns, detect anomalies in reassessments, and predict ownership stability.
With standardized assessor data covering 99.9% of U.S. properties – a staggering 155 million records – you have a massive dataset ready for actionable insights once it’s cleaned and organized.
Enriching Tax Data with Additional Layers
Tax data becomes exponentially more useful when enriched with financial, physical, and market-related datasets. These additional layers provide a fuller picture for decision-making:
- Financial Data: Mortgage records, lien details, and Automated Valuation Models (AVMs).
- Physical Characteristics: Features like the effective year built, construction quality, and roof material.
- Market Signals: Indicators such as listing status and ownership duration.
For instance, adding Effective Year Built and Quality of Construction to tax records can significantly enhance AVM accuracy.
Platforms like BatchData make this possible by offering a unified API that extends beyond core tax data to include property details, contact information, and even skip tracing. To ensure accuracy, every record should undergo CASS-certified address standardization with appended geocoordinates. This step is crucial for linking tax data with spatial datasets like zoning boundaries or flood zones without errors.
With enriched and cross-referenced data, how it’s delivered becomes just as important as how it’s processed.
Real-Time Applications and Bulk Delivery
The choice of delivery method depends on your use case. For instant lookups, RESTful JSON APIs are ideal, while bulk exports (CSV, Parquet) work best for large-scale analytics.
"What used to take 30 minutes now takes 30 seconds. BatchData makes our platform superhuman." – Chris Finck, Director of Product Management
Here’s a quick breakdown of delivery methods and their best applications:
| Delivery Method | Best For | Supported Formats |
|---|---|---|
| Real-Time API | Live lookups, underwriting, instant valuations | JSON |
| Bulk Data Export | Portfolio analytics, data warehousing, historical analysis | CSV, Parquet |
| Professional Services | Tailored integrations and custom pipelines | Custom |
For enterprise-scale operations, modern data stacks now support direct delivery via platforms like Snowflake Share, Google BigQuery, and Databricks Delta Share. This eliminates manual file transfers and allows seamless integration into existing data warehouses, making the process more efficient and scalable.
Conclusion: A Practical Path to Tax Data Standardization
Following the pipeline and governance strategies discussed earlier, the final step is creating a standardized API that ensures tax data consistency. Standardizing tax data for real estate APIs isn’t a one-and-done task – it demands ongoing engineering oversight. The process unfolds in clear stages: define a canonical schema with key fields like APN, assessed value, tax year, and exemption flags; establish a pipeline to ingest and transform raw county data into this schema; implement quality controls through automated validation and human review; and present the results via detailed API endpoints. Each step reinforces the next, boosting overall data reliability.
The biggest win from this structured approach? Less ambiguity across jurisdictions. When records follow a consistent format, downstream processes benefit from improved accuracy. This uniformity minimizes integration errors, speeds up partner onboarding, and enhances analytics for 155 million U.S. property records.
Ongoing governance is essential – keeping field definitions updated and tracking metadata ensures the pipeline remains dependable. Tax rolls evolve, counties adjust formats, and new exemption categories emerge. A production-grade pipeline stands out by monitoring anomalies in data volume or distribution, avoiding the pitfalls of a one-off build.
For teams looking to save time, BatchData offers a faster alternative. With assessor data updated daily for most counties, BatchData aggregates information from over 3,200 sources into a consistent schema. This means skipping the most labor-intensive steps. As BatchData explains:
"We accelerate your integration with data samples, expert mapping help, and prebuilt joins to accelerate your market integration."
Whether you build everything in-house or leverage pre-normalized data solutions to speed up delivery, the guiding principle remains the same: a clean, well-governed tax data schema is the backbone of reliable workflows – analytics, underwriting, enrichment, and automation all benefit. This unified strategy not only simplifies data integration but also supports smarter decision-making across real estate operations.
FAQs
What’s the best unique key for a parcel across counties?
The county assessor’s parcel number (APN) – sometimes referred to as PIN, PARCEL_ID, or TAXID – is the most reliable unique identifier for a parcel. However, because APN formats differ across jurisdictions, it’s best to standardize using a composite key. This involves combining the APN with the county’s jurisdiction identifier, such as the state FIPS code and county FIPS code. This approach helps maintain accuracy and prevents inconsistencies that can arise from relying on address-based data.
How do I handle different APN formats and county field names?
Managing different Assessor Parcel Number (APN) formats and inconsistent county field names across jurisdictions can be a real headache. That’s where a specialized property data API comes in. These tools standardize local records by using FIPS codes – unique identifiers for jurisdictions – to maintain data accuracy. For example, BatchData streamlines this process by delivering uniform, machine-readable property attributes. This makes it easy to search by address or APN and integrate the results directly into your workflows without any hassle.
How often should standardized tax data be refreshed in an API?
Standardized tax data in a real estate API needs daily updates to keep information accurate. This includes tax rates, billing details, and assessment changes across different regions. Frequent updates help avoid problems like incorrect jurisdiction codes or calculation mistakes that could interfere with transactions. BatchData ensures reliability by sourcing daily updates from more than 3,200 counties, providing up-to-date property tax, valuation, and ownership details.


