

Protecting property data APIs is crucial to avoid breaches, financial losses, and reputational damage. APIs in the PropTech industry handle sensitive information like ownership records, payment data, and IoT device integrations, making them prime targets for attacks. In 2024, the average cost of a U.S. property tech breach hit $9.36 million, and API-related vulnerabilities were a leading cause. Here’s how to secure your APIs effectively:
- Authentication and Access Control: Use OAuth 2.0, rotate API keys, and validate JWT tokens properly. Avoid static keys in code and enforce IP or service restrictions.
- Authorization: Implement role-based access control (RBAC), validate permissions for every request, and prevent broken object- and function-level authorization (BOLA/BFLA).
- Encryption: Use TLS 1.2+ for data in transit and AES-256 for data at rest. Avoid weak encryption methods and manage keys securely in an HSM or key vault.
- Rate Limiting: Apply strict rate limits, throttle requests, and cap payload sizes to prevent resource abuse and DDoS attacks.
- Monitoring and Logging: Centralize logs, redact sensitive data, and set up real-time alerts for anomalies. Regularly audit and test for vulnerabilities.
Neglecting these steps can lead to compliance penalties, loss of customer trust, and significant financial impact. Addressing API security is not just a technical task – it’s a business necessity.
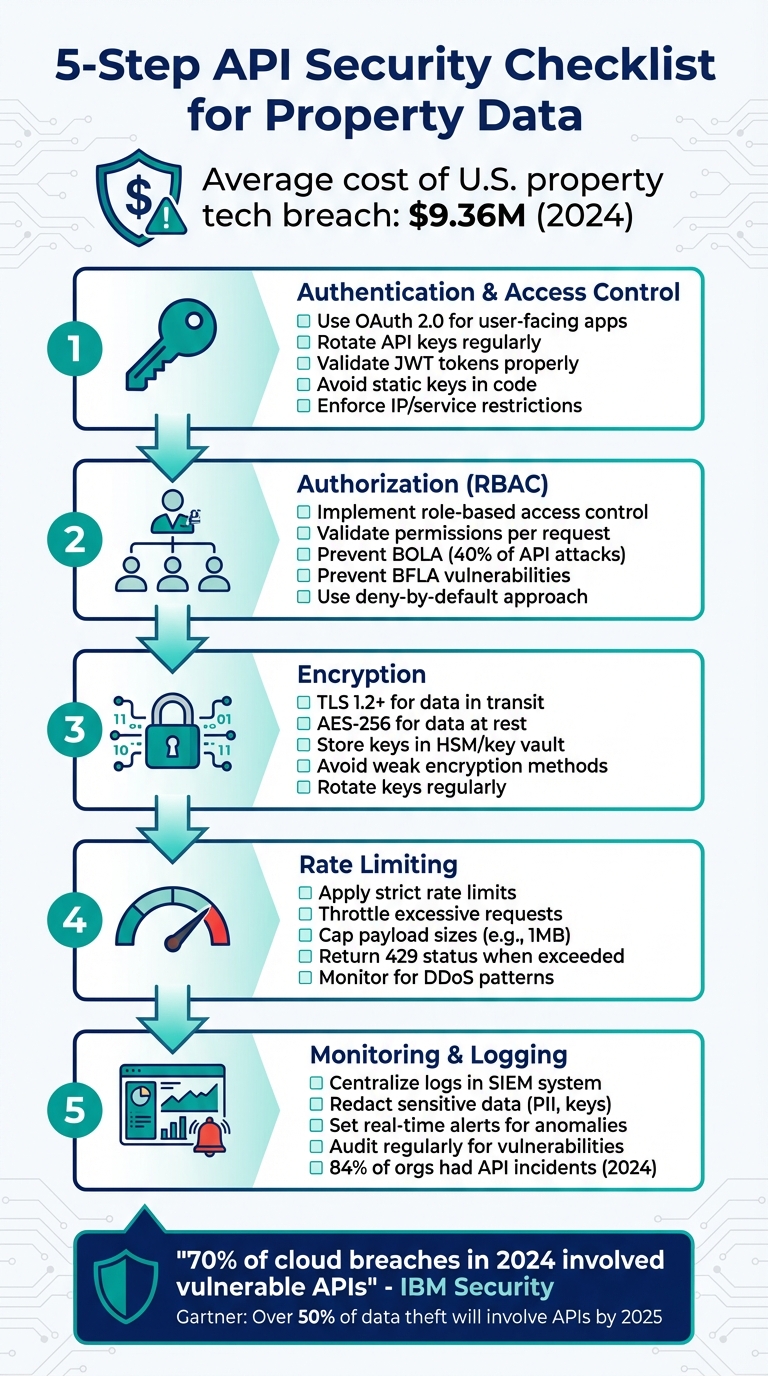
5-Step API Security Checklist for Property Data Protection
API Security: 10 Essential Measures Every Developer Must Know
sbb-itb-8058745
Access Control and Authentication
Access to real estate APIs should be restricted to authenticated users. Misconfigured systems or exposed static API keys can lead to leaks of sensitive information, including ownership details and financial records.
Static API keys are particularly risky when they appear in code repositories, logs, or network traffic. To mitigate these risks, use OAuth 2.0 for user-facing applications and rotate API keys regularly for machine-to-machine integrations. OAuth 2.0 eliminates the need for password sharing by using short-lived access and refresh tokens, significantly reducing the attack window.
"OAuth 2.0 tosses the old credential-sharing approach in the trash where it belongs, enabling secure, limited access through a clever token system." – Zuplo
When using API keys, avoid hardcoding them or committing them to repositories. Instead, store them in environment variables or use key management systems. Pass keys via HTTP headers (e.g., x-goog-api-key) rather than URL query parameters. To further secure API keys, apply restrictions like limiting usage to specific IP addresses, referrer URLs, or property search API services. These measures help reduce the impact of a compromised key.
Use OAuth 2.0 and Manage API Keys

OAuth 2.0 enhances security by clearly defining roles: the Resource Owner (user), the Client (application), the Authorization Server (identity provider), and the Resource Server (the API itself). This separation ensures that user passwords are never exposed, relying instead on short-lived tokens.
For added security, implement PKCE (Proof Key for Code Exchange) for all clients, aligning with OAuth 2.1 standards. This approach addresses vulnerabilities like code injection. Notably, RFC 9700, published in January 2025, explicitly prohibits the Resource Owner Password Credentials grant due to its inherent security risks.
"The resource owner password credentials grant MUST NOT be used. This grant type insecurely exposes the credentials of the resource owner to the client." – IETF RFC 9700
To protect redirection flows, configure the authorization server to use exact string matching for redirect URIs, preventing exploits like open redirect attacks. Limit token access by defining specific scopes (e.g., read:property_valuation) and audience parameters to ensure tokens are only valid for intended resources. Store access tokens in memory and refresh tokens in HttpOnly cookies to guard against cross-site scripting (XSS) attacks.
For sensitive operations, frequently rotate tokens using a dual-key strategy to ensure uninterrupted service. This involves generating a secondary key, updating the application, and revoking the old key immediately after deployment. Automate token rotation through CI/CD pipelines, and immediately rotate keys if a leak occurs or an employee is offboarded.
Validate JWT Tokens and Manage Sessions
JSON Web Tokens (JWTs) are stateless carriers of authorization data, but improper validation can lead to vulnerabilities, allowing attackers to manipulate tokens for unauthorized access.
Each service should independently validate JWTs, ensuring the alg header specifies an approved algorithm. Claims such as issuer, audience, and expiration must also be verified.
"JWTs are not secure just because they are JWTs, it’s the way in which they’re used that determines whether they are secure or not." – Curity
Use asymmetric signing so that tokens can be verified with only the public key. Public keys should be retrieved dynamically from a JSON Web Key Set (JWKS) endpoint, rather than being hardcoded. Cache these keys for a balance between performance and freshness, and allow up to 30 seconds of clock skew when validating time-based claims to account for minor server clock differences.
Set access token expiration times between 15 and 30 minutes, while refresh tokens can last 1 to 7 days. This approach limits the time attackers have to exploit stolen tokens. To handle revoked tokens, use a denylist in a fast storage solution like Redis to track token IDs (jti) until their expiration. Avoid including sensitive or personally identifiable information in the JWT payload, as it is Base64-encoded and easily decoded.
For web applications, store JWTs in cookies with HttpOnly, Secure, and SameSite=Strict attributes to protect against XSS attacks. Advanced implementations can bind tokens to specific TLS sessions (channel binding) or include a hash of the user’s device fingerprint to ensure requests originate from the authorized user.
These practices establish a strong foundation for secure access control and data protection. With authentication measures in place, the focus can shift to managing access rights through effective authorization policies in the next steps.
Authorization and Role-Based Access Control
After implementing strong authentication, the next step is ensuring robust authorization to prevent misuse of sensitive property data. Authorization defines what users are allowed to do, and any weakness here creates serious vulnerabilities. In fact, Broken Access Control was ranked as the #1 web security vulnerability in the OWASP 2021 Top 10, even though it’s relatively rare in software reports.
For property data APIs, it’s essential to validate permissions on every single request, even if the user is authenticated. Authentication alone doesn’t grant unrestricted access – permissions must be checked for each role (e.g., Agent, Appraiser, Admin) and action. Role-based access control (RBAC), attribute-based access control (ABAC), or relationship-based access control (ReBAC) can provide the necessary granularity based on the context.
A deny by default approach is critical here. Users should start with no permissions and only gain access explicitly granted for their role and actions. Centralizing authorization logic in middleware ensures consistent enforcement. For property-level authorization, it’s not just about granting access to an object but also to specific fields within it. For instance, a “Guest” might see a property’s address, but only a “Manager” should view the owner’s private contact details.
Let’s dive deeper into how to enforce object-level and function-level checks.
Prevent Broken Object-Level Authorization (BOLA)
BOLA occurs when an API fails to verify whether the authenticated user has permission to access a specific object, such as a property record. This vulnerability has been the #1 API security risk in the OWASP API Security Top 10 since 2019, with around 40% of API attacks linked to BOLA. Attackers exploit this by tampering with object identifiers in request URLs, headers, or payloads – e.g., changing an ID from 101 to 102 to access unauthorized records.
"The USPS hack is a classic example of a broken authorization vulnerability. User A was able to authenticate to the API and then pivot and access user B’s and 60 million other people’s information." – Dan Barahona, Head of Marketing at Biz Dev, APIsec
Authentication alone isn’t enough; ownership or explicit access rights must be verified for each resource. Property data APIs are especially vulnerable when they use predictable identifiers like sequential parcel IDs or internal database keys. Instead, replace these with random UUIDs and enforce ownership checks at the database level. For example, a query should look like:WHERE record_id = ? AND owner_id = ?
This ensures the requester has a legitimate connection to the data. Never rely on client-side checks or assume requests are safe just because they originate from your application. Adopting a zero-trust model ensures that every request is validated, regardless of user authentication.
Avoid generic serialization methods like to_json() that might expose all object properties. Instead, use Data Transfer Objects (DTOs) or explicitly select only the fields allowed for the user’s role. For data modification requests, whitelist editable fields to prevent mass assignment vulnerabilities, where unauthorized fields could be altered.
Secure Function-Level Authorization
Object-level checks protect individual records, but function-level controls safeguard entire operations. Broken Function-Level Authorization (BFLA) occurs when users access functions or endpoints they shouldn’t. For example, in property data APIs, BOLA might allow an agent to view a listing they don’t manage by changing an ID. BFLA, on the other hand, could enable the same agent to access a “Delete All Listings” function meant only for admins.
| Feature | BOLA | BFLA |
|---|---|---|
| Focus | Unauthorized data record access | Unauthorized function or endpoint access |
| Exploitation | Manipulating IDs (e.g., property_id=101 to 102) | Accessing restricted URLs or altering HTTP methods (e.g., GET to DELETE) |
| Key Defense | Object ownership checks and UUIDs | Role-based access control and admin-only controllers |
Sensitive operations – like bulk data exports, property modifications, or admin panel access – must be restricted to high-privilege roles. Don’t assume an endpoint is secure just because its URL isn’t public; attackers often guess paths like /api/v1/properties/export_all. Similarly, users should never gain access to sensitive actions by simply changing HTTP methods, such as switching from GET to DELETE or PUT.
To prevent this, use administrative controllers that inherit from abstract controllers with mandatory authorization checks for all child controllers. This keeps privileged logic separate from regular application code, reducing accidental exposure. Follow the least privilege principle by granting users only the access they need to perform their tasks. For highly sensitive admin accounts, consider Just-In-Time (JIT) access, which limits how long high-privilege access is available.
Log both successful and failed authorization attempts to detect suspicious activity or unauthorized access attempts. Regularly audit API endpoints for function-level flaws, paying close attention to the application’s business logic and group hierarchies. Authorization mechanisms should always reject access requests unless a role is explicitly granted permission.
These strategies work hand-in-hand with other security measures, like encrypted communications and rate limiting, to create a more secure system.
Data Protection in Transit and at Rest
Even with strong authentication and authorization measures in place, sensitive property data remains at risk if it’s not encrypted correctly. Encryption is essential – both during transmission and while stored – to protect data from being intercepted or accessed without permission.
Weak encryption can have serious consequences. For example, back in 2016, the National Institutes of Health (NIH) tackled this issue during the migration of their NCBI APIs to HTTPS. They conducted "blackout" tests to identify integrators still relying on unencrypted endpoints.
Use HTTPS with TLS 1.2+ and Security Headers
To protect property data APIs, always use HTTPS with TLS 1.2 or newer. Starting February 2024, AWS officially deprecated older TLS versions, making TLS 1.3 the recommended standard. Disable outdated protocols like SSLv2, SSLv3, TLS 1.0, and TLS 1.1, and enforce TLS 1.2+ with secure GCM-based ciphers. Avoid weak ciphers, such as NULL or Anonymous.
Certificates should use at least 2,048-bit RSA keys or equivalent ECDSA keys with SHA-256 hashing. Disable TLS compression to mitigate vulnerabilities like the CRIME attack.
For APIs, rejecting unencrypted HTTP requests with a 403 error is better than redirecting them to HTTPS. Many API clients don’t handle redirects properly, so skipping redirection avoids potential issues.
"API-only endpoints should disable HTTP altogether and only support encrypted connections. When that is not possible, API endpoints should fail requests made over unencrypted HTTP connections instead of redirecting them."
The Strict-Transport-Security (HSTS) header is crucial for enforcing HTTPS. Set it with max-age=63072000; includeSubDomains; preload to ensure HTTPS-only communication for two years – currently the best practice for secure environments.
To further secure APIs, use additional headers:
Cache-Control: no-store: Prevents sensitive data from being cached.X-Content-Type-Options: nosniff: Stops browsers from misinterpreting content types.Content-Security-Policy: frame-ancestors 'none': Blocks clickjacking by preventing the response from being embedded in iframes.
| Header | Value | Use |
|---|---|---|
Strict-Transport-Security | max-age=63072000; includeSubDomains | Enforces HTTPS-only connections for two years |
Cache-Control | no-store | Prevents sensitive data from being cached |
X-Content-Type-Options | nosniff | Stops browsers from misinterpreting content types |
Content-Security-Policy | frame-ancestors 'none' | Blocks responses from being embedded in iframes |
Encrypt Sensitive Data at Rest
When storing property data in databases, file systems, or backups, encryption is non-negotiable. AES with at least 128-bit keys (preferably 256-bit) is the standard for symmetric encryption. Use authenticated cipher modes like GCM (Galois/Counter Mode) or CCM to ensure both confidentiality and integrity. Avoid using Electronic Codebook (ECB) mode, as it fails to hide data patterns.
For added security, implement envelope encryption. This involves using a Data Encryption Key (DEK) for encrypting data and a separately stored Key Encryption Key (KEK) to protect the DEK. These keys should be managed in a Hardware Security Module (HSM) or a dedicated key vault.
"Vault’s barrier encrypts your data and Vault stores only encrypted data regardless of configured storage type."
Encryption keys should never be stored in plaintext, hard-coded in source code, or checked into version control. Use HSMs or managed key vaults that comply with FIPS 140-2 or 140-3 standards. Always generate keys using Cryptographically Secure Pseudo-Random Number Generators (CSPRNG), as standard PRNGs are predictable and unsafe for cryptographic use.
| Language | Secure Functions (CSPRNG) | Unsafe Functions (Avoid) |
|---|---|---|
| Java | java.security.SecureRandom | Math.random(), java.util.Random |
| Python | secrets() | random() |
| Node.js | crypto.randomBytes(), crypto.randomUUID() | Math.random() |
| PHP | random_bytes(), random_int() | rand(), mt_rand(), uniqid() |
| .NET/C# | RandomNumberGenerator | Random() |
| Go | crypto/rand package | math/rand package |
Enable encrypt-by-default settings to avoid plaintext storage. Regularly rotate encryption keys – either after processing about 295 exabytes of data or annually, whichever comes first. If a compromise is suspected, rotate keys immediately. NIST also advises using each key for a single purpose, such as encryption, authentication, or digital signatures.
For especially sensitive data exchanges, consider Mutual TLS (mTLS). With mTLS, both the client and server authenticate each other using certificates, providing a higher level of security than standard one-way TLS. This is particularly useful when working with trusted partners or internal systems.
Once encryption is properly implemented, the next step is managing API resource access with rate limiting.
Rate Limiting and Resource Management
Resource management works alongside authentication and authorization to protect API performance and stability.
Without proper rate limiting, a single API can quickly deplete resources and skyrocket costs. For example, a misconfigured API for SMS calls caused one company’s monthly bill to jump from $13 to $8,000.
Property data APIs face similar issues. Attackers can manipulate query parameters (e.g., changing size=200 to size=200000) to overwhelm database resources. To counter these threats, use layered controls that not only cap request counts but also manage execution timeouts, memory usage, file descriptors, and process limits.
Apply Throttling and Rate Limiting Policies
Rate limiting sets hard caps to block abuse, while throttling helps manage traffic spikes by delaying or queuing requests. When limits are exceeded, APIs should return a 429 Too Many Requests status along with headers like X-RateLimit-Limit, X-RateLimit-Remaining, and Retry-After to guide clients.
Avoid relying solely on IP addresses for user tracking, as shared networks (e.g., offices or mobile carriers) can cause the "noisy neighbor" problem. Instead, track users through API keys or JWT "sub" claims for better accuracy.
Different endpoints require different caps. Heavy operations such as property searches, report generation, or bulk exports might need stricter limits (e.g., 100–300 requests per minute) compared to simpler GET requests, which can handle 1,000+ RPM. For example, GitHub allows 5,000 requests per hour per user token, while Twitter permits 900 requests every 15 minutes on specific endpoints.
In distributed systems, use a centralized in-memory store like Redis to synchronize request counters across API nodes. Depending on your needs, choose between "strict" mode (ensures precise rate-limit checks before processing but adds latency) or "async" mode (checks in parallel for lower latency but may allow minor overages).
Monitor key indicators to refine your policies. High 429 rates could signal scraping attempts, bursts of 401/403 errors might indicate brute-force attacks, and elevated 5xx rates could point to backend resource strain. Implement progressive penalties: start with warnings, then throttle responses, escalate to temporary lockouts, and finally conduct manual reviews for persistent offenders.
These strategies work best when combined with the other security measures discussed earlier.
Set Payload Size Limits
Controlling payload size is another important way to protect system resources.
"API requests consume resources such as network, CPU, memory, and storage. The amount of resources required to satisfy a request greatly depends on the user input and endpoint business logic." – OWASP
Set limits at three levels: system-wide (to protect the gateway from DDoS attacks), API-level (to safeguard specific microservices), and endpoint-level (to secure resource-heavy functions like file uploads). For instance, Tyk Cloud Classic enforces a strict 1MB limit on all incoming requests.
When payloads exceed these limits, respond with a 413 Request Entity Too Large for system-wide violations or a 400 Request is too large for API or endpoint-specific issues. Beyond overall size, enforce limits on string lengths, array sizes, and other user inputs. Always validate server-side query parameters that control response size.
Keep file uploads under strict size limits (e.g., 1MB) and monitor complex GraphQL queries to avoid performance bottlenecks. Additionally, use compression ratio checks to defend against "Zip bombs" – small files that decompress into massive resource-hogging data.
If your API relies on paid third-party data providers, set hard spending limits or billing alerts to prevent runaway costs from excessive requests.
Monitoring, Logging, and Incident Response
Once you’ve implemented access control, authentication, rate limiting, and encryption, the next step is proactive monitoring. Why? Because even the most secure APIs can face incidents. In fact, a staggering 84% of IT and security professionals reported experiencing at least one API security incident in 2024.
"APIs have quietly become the primary target for cyberattacks. IBM Security reports that over 70% of all cloud breaches in 2024 involved vulnerable or exposed APIs." – Dan Barahona, API Security Expert, APIsec
Property data APIs, which handle sensitive details like addresses, ownership records, and financial information, are particularly attractive to attackers. Without robust monitoring and logging, these breaches can go unnoticed, leading to costly consequences.
Centralize Logging Without Storing Sensitive Data
Centralized logging is key to effective monitoring. Use a SIEM (Security Information and Event Management) system to compile logs from APIs, servers, and firewalls into one unified view. This approach allows you to identify patterns that might be missed when analyzing logs individually.
To protect sensitive data, automatically redact headers, API keys, and personally identifiable information (PII) from logs. For instance, mask credit card numbers as 1234-****-****-5678 or fully redact authorization tokens. While many organizations use static data masking (66%) and encryption (53%), missing encryption still accounts for 33% of data breaches.
Avoid capturing sensitive data by disabling tracing in production environments. Instead, use correlation IDs to trace API requests across services without logging sensitive identifiers. Additionally, encrypt stored logs using AES-256 or RSA to prevent unauthorized access if storage is compromised. Implement Role-Based Access Control (RBAC) or Attribute-Based Access Control (ABAC) to ensure only authorized personnel can access logs. Store these logs in a centralized, read-only location with restricted access to prevent tampering.
"Debug information should be only for your developers and network admins, not the API consumers." – Lukas Rosenstock, API Consultant
Structured logging in JSON format is ideal for SIEM compatibility. To ensure accurate traceability during investigations, synchronize time and date configurations across all systems. Also, avoid exposing internal systems by returning generic error messages to users instead of revealing database structures or server configurations.
Set Up Alerts and Intrusion Detection
With centralized and secured logs in place, the next step is real-time anomaly detection. Establish baselines for "normal" API activity to help monitoring tools identify unusual behavior, like a sudden jump from 100 to 10,000 requests per second. Set up alerts for anomalies such as error spikes, unexpected data transfers, or requests from unfamiliar origins.
"You can’t secure what you don’t know exists. Developers may deploy or test APIs without formal approval, creating untracked or undocumented endpoints (‘shadow APIs’)." – F5 Newsroom Staff, F5
Prepare for incidents by creating a detailed response plan. Define roles for key stakeholders, including Application Owners, Information Security teams, Legal counsel, and Executive leadership. Develop runbooks tailored to specific threats, such as DoS attacks or unauthorized access, to ensure swift and effective action. Keep in mind that compliance requirements like GDPR mandate notifying relevant authorities within 72 hours of a personal data breach, while Amazon’s Data Protection Policy requires notification within 24 hours.
When responding to an incident, secure and analyze logs that capture key details like timestamps, access attempts, and success or failure indicators. Maintain a chain of custody for forensic and legal purposes. Isolate affected systems, block malicious IPs, and document all containment actions.
After resolving an incident, conduct a thorough review. Document what happened, how it was addressed, and what corrective measures were implemented. Use these insights to update your incident response plan, and test it every six months or after major infrastructure changes.
Conclusion
Protecting property data APIs isn’t optional in a field that deals with sensitive financial, ownership, and personal details. With the average cost of a U.S. data breach projected to reach $9.36 million in 2024 and Gartner estimating that over half of data theft incidents will involve unsecure APIs by 2025, PropTech platforms face serious challenges.
This checklist outlines key steps to strengthen your API security: use OAuth 2.0 and JWT for authentication, enforce granular RBAC to limit access, encrypt data with TLS 1.3 and AES-256, apply rate limiting to prevent abuse, and maintain centralized logging with real-time alerts. These layers work together to create a robust defense strategy, ensuring that even if one measure fails, others remain in place to safeguard your data.
By adopting these practices, you build a strong security framework. Every integration matters – thoroughly vet third-party connections, continuously monitor for unusual activity, and treat API security as an ongoing priority. In the real estate industry, where APIs connect CRMs, payment systems, and IoT devices, every endpoint represents a potential risk.
For advanced solutions to secure your property data APIs, visit BatchData: https://batchdata.io
FAQs
How do I choose OAuth 2.0 vs API keys for my property data API?
When deciding on an authentication method, consider these use cases:
- OAuth 2.0 is the go-to choice for environments requiring secure, user-specific access, such as third-party integrations or multi-user systems. It uses temporary tokens and allows for fine-tuned permissions, making it a reliable option for scenarios where granular access control is critical.
- API keys work well for straightforward setups like internal tools or server-to-server communication. While they are easier to implement, they lack the advanced security and flexibility of OAuth 2.0, making them less ideal for high-security or scalable applications.
What’s the best way to stop BOLA when property IDs are guessable?
To address BOLA vulnerabilities when property IDs can be easily guessed, it’s crucial to implement strict authorization checks. This ensures users can only access resources they’re permitted to view.
Additionally, using parameter validation and anomaly detection can help identify and block any unauthorized access attempts. Together, these steps strengthen API security and safeguard sensitive property data.
What should I alert on to detect API abuse early?
To spot API abuse early, keep an eye on unusual traffic patterns that might hint at malicious behavior. For instance, set up alerts for unexpected spikes in traffic, multiple failed login attempts, or requests that go beyond set rate limits. These could point to activities like credential stuffing, scraping, or even DDoS attacks. Regularly reviewing traffic behavior and applying detection rules can help you catch suspicious actions quickly, allowing for a swift response to potential threats.


