


































Bad tax data leads to bad property calls. I’d sum it up like this: if I’m working from raw county records, I’m often dealing with missing fields, old values, owner-name mismatches, and parcel IDs that don’t line up across counties.
Here’s the short version:
- U.S. tax data is fragmented across 3,200+ county sources
- Assessed values often lag market changes, with a 1% market shift leading to less than a 0.30% change in assessed value over the next three years
- Raw records can miss:
- current ownership details
- district-level tax layers
- clean parcel matching
- usable property traits
- Enriched tax data fixes that by:
- standardizing APNs, addresses, and owner names
- linking parcels across jurisdictions
- mapping all tax districts tied to a property
- delivering cleaner records by real estate API or bulk files
- The result is better underwriting, cleaner valuation work, stronger targeting, and fewer manual checks
If I had to put it in one sentence: tax data enrichment turns scattered public records into property data I can trust for ownership checks, tax review, and portfolio analysis.
Quick comparison
| Area | Raw Tax Data | Enriched Tax Data |
|---|---|---|
| Coverage | Varies by county | Joined across many sources |
| Ownership | Last recorded owner only | Linked owner records across parcels |
| Values | Often stale | Matched with dates and history |
| Jurisdictions | Partial tax view | Mapped to county, city, school, and special districts |
| Workflow | Heavy cleanup needed | Ready for analysis and delivery |
So when I want a clearer property view for real estate investing, I don’t just need more records. I need clean matching, current updates, and full tax-jurisdiction mapping.
sbb-itb-8058745
Why tax data gaps distort property decisions
When records get split across systems, property decisions start to drift. Valuation gets messy. Ownership checks get shaky. Tax exposure becomes harder to read with confidence.
How fragmented county and district records create conflicting property views
A single parcel can sit inside county, city, school, and special districts at the same time. Each may keep its own records, naming rules, and file format. If there’s no shared identifier, that one parcel can turn into duplicate entries or records that never match up across datasets.
That leads to duplicate records, missed matches, and partial property profiles. A portfolio manager might pull the same asset and see different assessed values depending on the source. Now the team has to sort out which record is right, and that gets harder fast. Across a large portfolio, it can throw off analysis in a big way.
How outdated tax and ownership fields weaken analysis
Old tax data creates a different kind of problem. On average, a 1% change in market value results in less than a 0.30% change in assessed values over the following three years. That lag matters. Tax assessments often trail market movement, so records may overstate or understate value for years.
Ownership fields have the same issue. Recorded ownership only shows the last certified update. Pending sales and unrecorded transfers may not show up until the next certified update. So an acquisition team may reach out to the wrong party using ineffective outreach tools, or miss a recent transfer that changes whether a deal still works. Put simply, recorded ownership can point to the wrong party until the next certified update.
Why cross-jurisdiction mapping is the hardest technical problem
Cross-jurisdiction mapping is more than a formatting headache. It’s a structural issue. A property can shift from one district’s rules to another’s when boundary lines change. When that happens, the property may end up with a different tax rate, a different parcel format, and a different update schedule.
Standardizing APNs, legal descriptions, and FIPS codes across 3,200+ county sources requires continuous boundary tracking and outage tolerance. Without that setup, cross-jurisdiction analysis turns inconsistent. And inconsistent analysis leads straight to bad property calls.
These gaps don’t all hit in the same place. They show up across identification, value, ownership, and property traits.
| Data Category | Key Fields Affected | Impact of Mapping Gaps |
|---|---|---|
| Property Identification | APN, FIPS Code, Legal Description | Duplicate records; failed cross-district matching |
| Values & Taxes | Assessed Value, Market Value, Tax Amount | Inaccurate valuation; flawed investment analysis |
| Ownership Details | Owner Name, Vesting Info, Mailing Address | Failed ownership verification; ineffective targeting |
| Characteristics | Square Footage, Year Built, Construction Type | Incorrect insurance underwriting; poor comparable matching |
That’s why enrichment has to start with normalization and matching, not just adding more records. Before any team can trust the output, those records need to be normalized, matched, and checked so they can support actual analysis.
What tax data enrichment adds to a property record
Raw tax records are official, but they don’t tell the whole story. You usually get the assessed value and the owner of record. That’s a start. But for analysis, it often isn’t enough.
Once records are matched and enriched, those missing details start to come into focus. That means fewer manual lookups, better targeting, and cleaner models.
Key tax and assessment fields that improve insight quality
The fields that matter most are often the ones county-level fragmentation tends to hide, split up, or skew. The table below shows the main enrichment fields and how teams use them day to day.
| Enrichment Field | What It Captures | Decision It Supports |
|---|---|---|
| Assessed Value | Official value for tax purposes | Tax equity research and forecasting |
| Land vs. Improvement Value | Breakdown between land and structures | Insurance underwriting and replacement cost models |
| Tax Status / Exemptions | Homestead exemptions and delinquency status | Compliance checks and property screening |
| Property Use Codes | Standardized classification (e.g., multi-family, retail) | Market segmentation and targeted outreach |
| Owner Mailing Address | Current address of the deed holder | skip tracing property owners for absentee owner targeting |
| APN / FIPS Code | Parcel and jurisdiction identifiers | Cross-source linking and boundary mapping |
These fields help patch the holes left by fragmented county records.
How normalization and matching make records usable
Fields only help if the records connect cleanly. Enrichment platforms standardize county codes, addresses, and owner names into one shared schema. That step lets a team match a tax record to a GIS boundary file, a deed record, and a mailing database without manual cleanup.
It also cuts out duplicates that show up when the same parcel appears under slightly different IDs across sources. Without that step, even solid source data can turn into a mess.
How enriched data is typically delivered
Delivery matters just as much as the data itself. For real-time workflows, a REST API is the standard. It returns property profiles in real time and replaces manual county lookups.
For large-scale analysis or model training, bulk delivery through SFTP or FTP in CSV or Parquet format usually makes more sense. BatchData supports real-time API access and bulk CSV or Parquet extracts for enrichment at scale.
Those standardized records are what let teams use tax data in underwriting, outreach, and portfolio analysis.
How enriched tax data improves decisions across real estate workflows
Enriched tax data helps with ownership, valuation, and tax-risk analysis because it turns messy tax rolls into records teams can actually use. Once records are normalized, the next move is simple: use that data to make better calls.
Ownership research, valuation support, and portfolio analysis
Enriched ownership data ties parcel records into a single owner view. That means an investor can spot all parcels connected to the same LLC or family trust across multiple states without doing manual cleanup line by line.
For valuation, raw assessed values often trail the market by one or more tax cycles. Some places also cap annual increases, which can make side-by-side comparisons messy. Enriched records add the last reassessment date, prior-year values, and local assessment ratios. That gives analysts a cleaner way to normalize values across markets.
They can also bring hidden tax details to the surface. For example, tax abatements and exemption expiration dates are often buried in raw files. Enriched records pull those items out, so teams can see where tax expense may rise later.
The same record also makes tax-burden review and jurisdiction analysis much easier.
Underwriting, market targeting, and risk review
For lenders and insurers, one of the biggest problems with raw tax data is that it can miss part of the total tax bill. A property might sit inside a Municipal Utility District, a school district, and a city taxing authority at the same time. Raw county exports may leave out one or more of those layers.
Enriched data fixes that by mapping parcels to all relevant taxing jurisdictions with GIS overlays. Once those jurisdictions are mapped, underwriters can calculate total tax liability instead of working from a partial estimate.
A common trigger is a change in ownership status. If a home that used to be owner-occupied loses its homestead exemption, the effective tax rate can jump a lot. Enriched pipelines that compare exemption flags year over year catch that shift automatically. That gives underwriters time to adjust debt-service coverage assumptions before closing.
Those mapped tax layers flow straight into underwriting and risk review.
Raw tax data vs. enriched tax data: side-by-side comparison
The gap stands out fast when you compare raw and enriched records side by side.
| Dimension | Raw Tax Data | Enriched Tax Data |
|---|---|---|
| Completeness | Many missing fields; varies widely by county | Key fields backfilled from multiple sources; 155M+ properties covered |
| Jurisdiction consistency | Local codes and formats differ; hard to join across geographies | Standardized schemas across states, including city, school, and special districts |
| Update reliability | Monthly or quarterly; no change tracking | Daily refresh cycles; refresh dates exposed per parcel |
| Ownership clarity | Inconsistent names; no cross-parcel linkage | Entity resolution links owners across parcels and jurisdictions |
| Workflow impact | Requires heavy ETL before it can support analysis | Ready for underwriting, portfolio analysis, and targeting |
How to implement tax data enrichment and keep it accurate
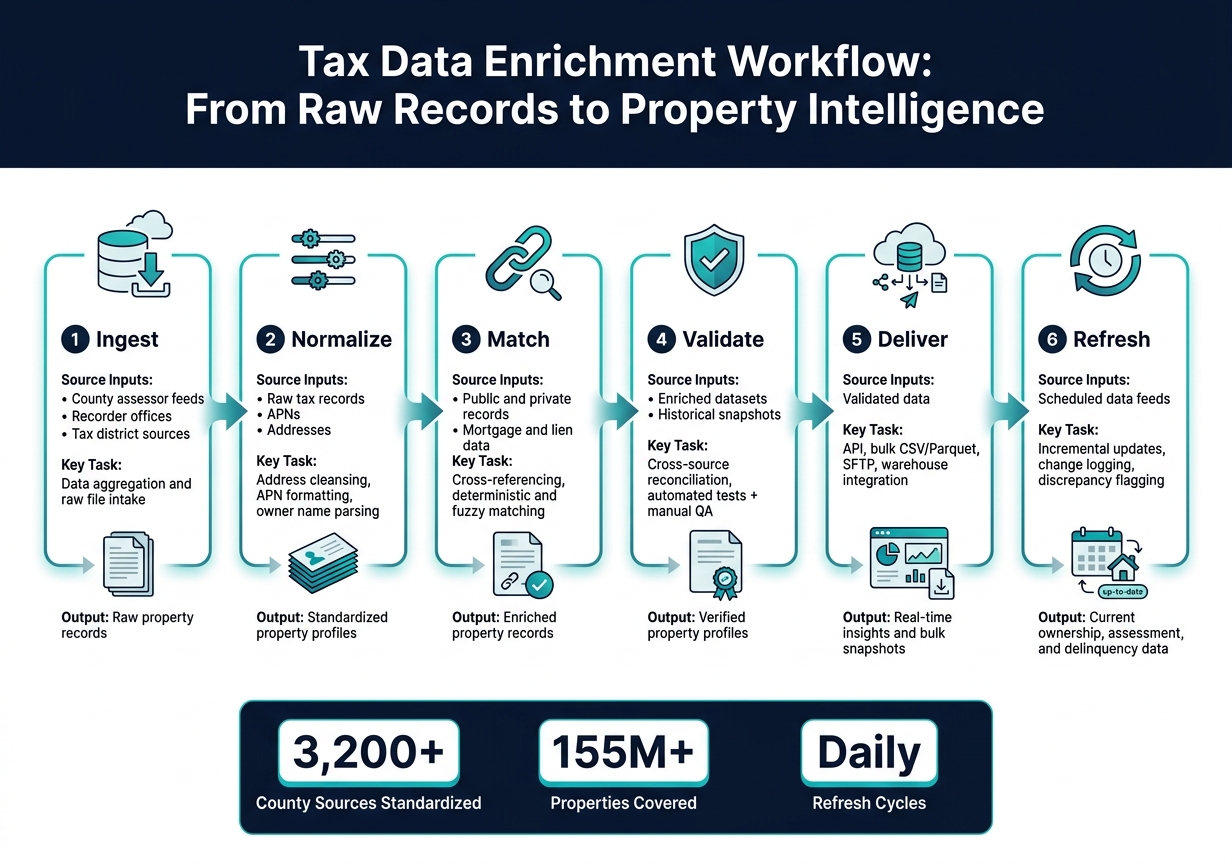
Tax Data Enrichment Workflow: From Raw Records to Property Intelligence
A step-by-step workflow from tax records to usable property intelligence
Once records are normalized and matched, the workflow is pretty simple: turn raw tax files into usable property intelligence through six stages – ingest, normalize, match, validate, deliver, and refresh.
It begins with data ingestion. Teams pull tax rolls, assessment files, and parcel shapefiles from county assessors, recorders, and tax districts. Those raw files go into a staging area, along with metadata that tags the source, jurisdiction, schema, and effective date.
Next comes normalization. This step brings parcel IDs, addresses, and owner name fields into one consistent schema. Without that cleanup, even basic analysis can get messy fast.
After that, record matching links records across counties and tax districts. The process usually starts with deterministic rules, then moves to fuzzy matching to catch misspellings and formatting gaps. When parcel IDs and addresses don’t line up cleanly – common with rural parcels – spatial joins help close the gap.
Then comes validation. Automated checks confirm that land value plus improvement value equals total assessed value. They also flag unusual year-over-year changes when there’s no recorded sale or permit, and they reconcile conflicts between assessor and recorder sources. If a record falls into a gray area, it goes to manual QA before publication.
From there, enriched records are delivered through the channel that fits the team’s setup:
- API
- Bulk CSV or Parquet files
- SFTP
- Direct warehouse integration
Versioned, date-stamped records matter here. They let analysts rebuild a property’s tax history instead of looking at just a single snapshot.
Process table: inputs, normalization, validation, and outputs
The table below shows how each stage connects its inputs, checks, and outputs.
| Workflow Stage | Source Inputs | Standardization Tasks | Validation Checks | Final Insight Outputs |
|---|---|---|---|---|
| Ingestion | County assessor feeds, recorder offices, and tax district sources | Data aggregation and raw file intake | Source availability and connectivity checks | Raw property records |
| Normalization | Raw tax records, APNs, addresses | Address cleansing, APN formatting, owner name parsing | Format consistency and schema validation | Standardized property profiles |
| Matching | Public and private records, mortgage and lien data | Cross-referencing, deterministic and fuzzy matching | Identity resolution and duplicate detection | Enriched property records |
| Validation | Enriched datasets, historical snapshots | Cross-source reconciliation, temporal checks | Automated run tests plus manual QA | Verified property profiles |
| Delivery | Validated data | API, bulk CSV or Parquet, SFTP, warehouse integration | Uptime and latency monitoring | Real-time insights and bulk snapshots |
| Refresh | Scheduled data feeds | Incremental updates, change logging | Discrepancy flagging and audit logs | Current ownership, assessment, and delinquency data |
Conclusion: Better tax data leads to better property decisions
Raw tax data is fragmented across jurisdictions, schedules, and field definitions. That makes property decisions riskier than they need to be.
The key step is mapping a parcel to every tax authority tied to it. That’s what makes total tax liability visible. It also improves underwriting, portfolio analysis, and market targeting.
BatchData – Ivo Draginov provides enriched feeds, APIs, bulk delivery, and integration support. Once the pipeline is in place, teams can work from current ownership, assessment, and delinquency data instead of stale tax rolls.
FAQs
How is enriched tax data different from raw county records?
Enriched tax data takes messy, uneven county records and turns them into a standardized format you can actually use.
Raw county data often changes from one location to the next. Addresses may be formatted differently, field names might not match, and some records can feel patchy or incomplete.
Enrichment cleans up and organizes that data. Then it checks it against other sources to fill in missing pieces and add details like market trends and ownership history.
The result is a deeper, more reliable property profile.
Why do assessed values often lag behind market value?
Assessed values often trail market value. Why? Because local tax authorities set them for tax purposes, not to match every swing in the housing market.
That means an assessed value usually reflects the last certified update, not what a home might sell for today. If prices in an area have moved fast, up or down, the assessed value may not keep up. Research also shows that assessed values tend to change more slowly over a 3-year period, especially when the market is falling.
How often should tax-enriched property data be refreshed?
Tax-enriched property data should be refreshed daily so real estate decisions are based on current information, not stale records.
With daily updates to tax assessments, property values, and ownership details, teams can track tax liens, catch assessment changes early, and cut risk by working from the latest data available.


